


Next: Partial List of
Up: Results from Prior
Previous: Constable
Pingali has been supported by the following NSF grants.
##1##1- NSF Presidential Young Investigator award: 1989-94, $312,500.
Project title: Parallel Computation: Languages, Architectures and
Compilers.
- NSF grant number CCR-9008526: 1990-1992, $81,262.
Project Title: Parallel Languages, Parallelizing Compilers.
This funding supported research in two areas: (i) program analysis
and optimization, and (ii) automatic restructuring of programs.
In the area of program analysis and optimization, Pingali
developed fast algorithms for control dependence analysis, and
investigated the use of `sparse' techniques for speeding up program
analysis. These algorithms and their impact are described below.
- Control dependence is usually represented using the control
dependence graph (CDG), a data structure designed by Ferrante,
Ottenstein and Warren [38]. The CDG provides access to
control dependence predecessors and successors in time proportional to
the size of these sets, but in the worst case, its size is quadratic
in the size of the program. Cytron, Ferrante and
Sarkar [31], and Sreedhar and Gao [105], among
others, have tried to reduce this size while preserving proportional
time access but these efforts have not been fruitful, and this problem
was the major open problem in the area of control dependence. Pingali
and his co-workers have given an optimal solution to this problem by
defining a data structure called the augmented postdominator
tree (
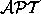 ), which can be built in space and time proportional
to the size of the program, and which provides proportional time
access to control dependence successors and
predecessors [89]. It is being used at IBM (Kemal Ebcioglu's
group) for speculative instruction scheduling, and at HP (Bob Rau's
group) for dataflow analysis of code with speculative operations. In
addition, the
), which can be built in space and time proportional
to the size of the program, and which provides proportional time
access to control dependence successors and
predecessors [89]. It is being used at IBM (Kemal Ebcioglu's
group) for speculative instruction scheduling, and at HP (Bob Rau's
group) for dataflow analysis of code with speculative operations. In
addition, the 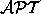 data structure can be used to construct the
SSA form of a program in linear time, which improves the quadratic
time complexity of the most commonly used algorithm, due to Cytron,
Ferrante, Rosen, Wegman and Zadeck [30].
data structure can be used to construct the
SSA form of a program in linear time, which improves the quadratic
time complexity of the most commonly used algorithm, due to Cytron,
Ferrante, Rosen, Wegman and Zadeck [30].
- Pingali and his students have designed an optimal solution to the
problem of determining control dependence equivalence
classes [59]. This algorithm is being used at Microsoft
by Daniel Weise's group; for some programs, it speeds up SESE region
determination by a factor of 40 over previous algorithms (personal
communication from Roger Crew). Flavors Technology Inc. is using this
algorithm for SESE region determination (personal communication from
Doug Currie).
- Pingali's research group has defined and implemented the
dependence flow graph (DFG) which is an executable representation
of program dependences, and which can be used to perform a variety
of forward and backward dataflow analysis, such as constant
propagation, elimination of partial redundancies, and strength
reduction, using sparse techniques [59,58]. The
DFG is being used as an internal representation of digital circuits
by Miriam Leeser's logic synthesis and verification group in the EE
department at Cornell University; this group uses the DFG tool-kit
implemented by Pingali's research group [19,64].
In the area of automatic restructuring techniques for programs, Pingali and his group have performed the following work.
- There is a lot of interest in the community in using matrix
methods to model and synthesize sequences of loop transformations
(permutation, skewing, reversal), a technique pioneered by Banerjee,
and by Wolf and Lam [6,125,124]. This work has
focused on using unimodular matrices. Pingali and his students have
generalized these techniques by showing that general non-singular
matrices can be used to model these loop transformations, and by
showing that efficient code can be generated through the use of the
Hermite normal form decomposition. A paper describing these results
won the best paper prize at ASPLOS 1992 [65]; this paper was
also selected for publication in a special issue of ACM
Transactions on Computer Systems [66]. Pingali and his
students have used these techniques to restructure programs to
expose parallelism for coarse-grain architectures, and to enhance
locality of reference in programs running on machines with caches.
These ideas are being incorporated into a production FORTRAN
compiler by Peter Morris' group at HP, Chelmsford, MA.
- Pingali and his students have developed a fast and general
algorithm for automatic data alignment [9]. The model of
alignment used by this algorithm unifies so-called axis, stride and
offset alignments (defined by Chatterjee, Gilbert and
Schreiber) [20,21], and is
more general because it includes skew alignments (defined by
Anderson and Lam) [5].
Next: Partial List of
Up: Results from Prior
Previous: Constable
nuprl project
Tue Nov 21 08:50:14 EST 1995