See title page for important information about this reference
Next: Proof Tactics Up: Index Previous: Proofs Contents
See title page for important information about this reference
We may view Nuprl as a programming language in which the proofs are programs which are ``translated'' into terms and ``run'' via an evaluator. Proving the truth of a statement in the system is equivalent to showing that the type corresponding to the statement is inhabited, and proving that a type is inhabited in a constructive setting requires that the user specify how an object of the type be built. Implicitly associated with each Nuprl proof, then, is a term whose type is specified by the main assertion being proved. This term exhibits the properties specified by the assertion it corresponds to; if we think of a programming problem as being a list of specifications, then a proof that the specifications can be met defines an algorithm which solves the problem, and the associated term becomes the computational realization of the algorithm. The system also supplies a means for evaluating these terms. Given a term the evaluator attempts to find a value corresponding to the term. For more on the correspondence between proofs and programs see [Bates & Constable 85] and [Sasaki 85].
In this chapter we consider Nuprl as a programming tool. We describe generally the way in which the system extracts terms from proofs and computes the values of terms, and we conclude the chapter with an example which demonstrates the workings of the extractor and the evaluator.
A proof gives rise to a term in that each rule used in the proof
produces an extract form whose parameters are instantiated
with the terms
inductively extracted from the subgoals generated by the rule invocation.
For example, if we wish to prove a theorem of the form ![]() using the
intro rule for disjoint union we must prove either
using the
intro rule for disjoint union we must prove either ![]() or
or ![]() as
a subgoal.
Assuming we prove
as
a subgoal.
Assuming we prove ![]() and assuming
and assuming ![]() is the term inductively extracted
from the proof of
is the term inductively extracted
from the proof of ![]() then inr(
then inr(![]() ) becomes the term extracted
from the proof of
) becomes the term extracted
from the proof of ![]() , for inr(
, for inr(![]() ) is the extraction form
for the right intro rule for disjoint unions.
Note that if
) is the extraction form
for the right intro rule for disjoint unions.
Note that if ![]() is in type
is in type ![]() then inr(
then inr(![]() ) is in
) is in ![]() , so the
extraction makes sense.
Similarly, if we prove something of the form
x:
, so the
extraction makes sense.
Similarly, if we prove something of the form
x:![]() »
» ![]() using the elim rule for disjoint union on the hypothesis,
then Nuprl generates two subgoals.
The first requires us to show that if
using the elim rule for disjoint union on the hypothesis,
then Nuprl generates two subgoals.
The first requires us to show that if ![]() is true (i.e.,
is true (i.e., ![]() appears in
the hypothesis list)
then
appears in
the hypothesis list)
then ![]() is true.
The second requires us to show that if
is true.
The second requires us to show that if ![]() is true (i.e.,
is true (i.e., ![]() appears in
the hypothesis list)
then
appears in
the hypothesis list)
then ![]() is true.
If
is true.
If ![]() is the term extracted from the the first subgoal
(
is the term extracted from the the first subgoal
(![]() is a term with
is a term with ![]() a free variable whose type is
a free variable whose type is ![]() ;
recall that
;
recall that ![]() represents our assumption of the truth of
represents our assumption of the truth of ![]() in the
first subgoal)
and
in the
first subgoal)
and ![]() is the term extracted from the second subgoal,
then
decide(
is the term extracted from the second subgoal,
then
decide(![]() )
is the term extracted from the proof of
x:
)
is the term extracted from the proof of
x:![]() »
» ![]() .
Note that if
.
Note that if ![]() corresponds to inl(
corresponds to inl(![]() ) for some
) for some ![]() in
in ![]() then from the computation rules the extracted term is equivalent to
then from the computation rules the extracted term is equivalent to
![]() ; since
; since ![]() proves
proves ![]() under the assumption of
under the assumption of ![]() and
and ![]() holds (since
holds (since ![]() is in
is in ![]() ) the extracted term works as
desired.
Similarly, the term behaves properly if
) the extracted term works as
desired.
Similarly, the term behaves properly if ![]() has value inr(
has value inr(![]() )
for some
)
for some ![]() in
in ![]() ; thus this extraction form is justified.
; thus this extraction form is justified.
One should note that certain standard
programming constructs have
analogs as Nuprl terms.
In particular, recursive definition corresponds to the ind(![]() )
form, which is extracted from proofs which use induction via the elim
rule on integers.
decide(
)
form, which is extracted from proofs which use induction via the elim
rule on integers.
decide(![]() ) represents a kind of if-then-else
construct,
while the functional terms extracted from proofs using functional intro
correspond to function constructs in a standard programming language.
) represents a kind of if-then-else
construct,
while the functional terms extracted from proofs using functional intro
correspond to function constructs in a standard programming language.
To display the term corresponding to a theorem ![]() one evaluates a special
Nuprl term, term_of(
one evaluates a special
Nuprl term, term_of(![]() ), which
constructs the extracted term of
), which
constructs the extracted term of ![]() in a
recursive fashion.
Briefly, the extraction form of the top refinement rule becomes the outermost
form of the term being constructed.
The parameters of the form then become the terms constructed from the subgoals
generated by the refinement rule.
in a
recursive fashion.
Briefly, the extraction form of the top refinement rule becomes the outermost
form of the term being constructed.
The parameters of the form then become the terms constructed from the subgoals
generated by the refinement rule.
Many Nuprl rules require the user to prove that a type is
well-formed,
i.e., that the type resides in some universe ![]() .
These subgoals, when proved, yield the extraction term
axiom
and are usually ignored by term_of as it builds the term for
a theorem.
.
These subgoals, when proved, yield the extraction term
axiom
and are usually ignored by term_of as it builds the term for
a theorem.
We should note here that one can manipulate canonical and noncanonical terms explicitly in the system. For example, the following definition defines an absolute value function.
abs(<x:int>) == less (<x>; 0; -<x>; <x>)
We may now use abs as a definition in the statement and proof of theorems.
This capability adds a great deal of flexibility to the system.
A given term may contain many noncanonical subterms, so some strategy for choosing the subterm to be reduced is essential. It may not be necessary to reduce all the noncanonical subterms, as a canonical term can contain noncanonical subterms. The strategy chosen is a lazy strategy in that it chooses a minimal number of reductions needed to reduce the term to canonical form. The evaluator cannot always succeed since there are terms which have no canonical form. However, the evaluator will succeed on any term which can be assigned a type.
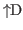 .
.
For example, suppose we have a theorem named bruce with main goal
>> x:int -> y:int # (x=y in int)
proved so that the extracted term is ... ... |P>eval | |E>let p1 = \x.spread(x;u,v.u);; | |\x.spread(x;u,v.u) | |E>let t = term_of(bruce);; | |\x.<x,axiom> | |E>t(17);; | |<17,axiom> | |E>p1(t(17));; | |17 | ... ...
The Nuprl command create ![]() eval
eval ![]() creates a library
object that can contain any number of bindings (all terminated by
;;).
The library objects created in this way are edited using ted and so
may contain def refs.
Checking an EVAL object augments the EVAL environment by
evaluating the bindings it contains.
All EVAL objects in a library are evaluated when the library is loaded.
creates a library
object that can contain any number of bindings (all terminated by
;;).
The library objects created in this way are edited using ted and so
may contain def refs.
Checking an EVAL object augments the EVAL environment by
evaluating the bindings it contains.
All EVAL objects in a library are evaluated when the library is loaded.
Thm1 >>all x:int. square(x) | ~ square(x).
Thm2 >>all x:int. square(x) vel ~ square(x).
The first theorem can be proved by introducing
The second theorem has a trivial proof. We simply use the fact that
![]() vel ~
vel ~![]() holds for any proposition
holds for any proposition ![]() and take rootf(x)*rootf(x)=x in int
as
and take rootf(x)*rootf(x)=x in int
as ![]() . However, there is no interesting computational content to this
result; we do not obtain from it a procedure to decide whether
. However, there is no interesting computational content to this
result; we do not obtain from it a procedure to decide whether ![]() is a
square. (The interested reader should prove this theorem and display
its computational content.)
is a
square. (The interested reader should prove this theorem and display
its computational content.)
The following is a small proof in Nuprl with the extraction clauses
shown explicitly. The system does not produce the comments (* ![]() *);
we include them for illustrative purposes only.
In the interest of condensing the presentation we also elide hypothesis lists wherever possible.
*);
we include them for illustrative purposes only.
In the interest of condensing the presentation we also elide hypothesis lists wherever possible.
,------------------------------------------------------------, |EDIT THM thm | |------------------------------------------------------------| |* top (* term_of(thm) extracted *) | |>> all x,y:int.(x=y in int)|some z:int.~(z=0 in int)#(x+z=y | | in int | | | |BY quantifier (* ext \x.\y.e1 (quantifier tactic does | | intro twice) *) | |1* 1. x:(int) | | 2. y:(int) | | >> ((x=y in int)|some z:int.~(z=0 in int)#(x+z=y in int))| | (* ext e1 *) | |2* >> (int) in U1 | | | |3* >> (int) in U1 | '------------------------------------------------------------' |
The rule quantifier is a tactic, a
user-defined rule of inference,
which successively applies the intro rule to each
universal quantifier;
in this case it performs two applications. This tactic was written by
a user of the system and must be loaded as an ML object to be used;
in general it would not be available.
See the following chapter for more on tactics.
The extracted term is a function
which, given any values for ![]() and
and ![]() , will give a proof of the body; this
corresponds to the intuitive meaning of all and justifies its definition
as a dependent function. Note that
, will give a proof of the body; this
corresponds to the intuitive meaning of all and justifies its definition
as a dependent function. Note that ![]() is the term extracted
from the first subgoal; the next window shows the proof of this subgoal.
is the term extracted
from the first subgoal; the next window shows the proof of this subgoal.
,------------------------------------------------------------, |EDIT THM thm | |------------------------------------------------------------| |* top 1 (* e1 extracted *) | |1...2. | |>> ((x=y in int)|some z:int.~(z=0 in int)#(x+z=y in int)) | | | |BY seq (x=y in int)|~(x=y in int) new E (* ext \E.e3(e2) *) | | | |1* 1...2. | | >> (x=y in int)|~(x=y in int) (* ext e2 *) | | | |2* 1...2. | | 3. E:(x=y in int)|~(x=y in int) | | >> ((x=y in int)|some z:int.~(z=0 in int)#(x+z=y in int))| | (* ext e3 *) | '------------------------------------------------------------' |
The seq rule extracts a function which in effect substitutes
the proof of the seq term, ![]() , for each instance of its
use in
, for each instance of its
use in ![]() (under the name E).
(under the name E).
,------------------------------------------------------------, |EDIT THM thm | |------------------------------------------------------------| |* top 1 1 (* e2 extracted *) | |1...2. | |>> (x=y in int)|~(x=y in int) | | | |BY arith (* ext int_eq(x;y;inl(axiom);inr(axiom)) *) | | | |1* 1...2. | | >> x in int | | | |2* 1...2. | | >> y in int | | | |3* 1...2. | | >> x in int | | | |4* 1...2. | | >> y in int | '------------------------------------------------------------' |
The arith decision procedure produces the int_eq term, a decision procedure for equality on the integers.
,------------------------------------------------------------, |EDIT THM thm | |------------------------------------------------------------| |* top 1 2 (* e3 extracted *) | |1...2. | |3. E:(x=y in int)|~(x=y in int) | |>> ((x=y in int)|some z:int.~(z=0 in int)#(x+z=y in int)) | | | |BY elim 3 (* ext decide(E;l.e4;r.e5) *) | | | |1* 1...3. | | 4. l:(x=y in int) | | >> ((x=y in int)|some z:int.~(z=0 in int)#(x+z=y in int))| | (* ext e4 *) | |2* 1...3. | | 4. r:~(x=y in int) | | >> ((x=y in int)|some z:int.~(z=0 in int)#(x+z=y in int))| | (* ext e5 *) | '------------------------------------------------------------' |
The elim rule for disjoint unions produces a decide term. In the next frame the term l is extracted from the first subgoal because our goal is exactly l (the actual proof of this subgoal is not shown but is carried out using the rule hyp 4).
,------------------------------------------------------------, |EDIT THM thm | |------------------------------------------------------------| |* top 1 2 1 (* e4 extracted *) | |1...3. | |4. l:(x=y in int) | |>> ((x=y in int)|some z:int.~(z=0 in int)#(x+z=y in int)) | | | |BY intro left (* ext inl(e6) *) | | | |1* 1...4. | | >> (x=y in int) (* ext e6==l (follows by hyp 4) *) | | | |2* 1...4. | | >> some z:int.~(z=0 in int)#(x+z=y in int) in U1 | '------------------------------------------------------------' |
In the next frame r is extracted for the same reason as l is above.
,------------------------------------------------------------, |EDIT THM thm | |------------------------------------------------------------| |* top 1 2 2 (* e5 extracted *) | |1...3. | |4. r:~(x=y in int) | |>> ((x=y in int)|some z:int.~(z=0 in int)#(x+z=y in int)) | | | |BY intro right (* ext inr(e7) *) | | | |1* 1...4. | | >> some z:int.~(z=0 in int)#(x+z=y in int) (ext e7 *) | | | |2* 1...4. | | >> ((x=y in int)) in U1 | '------------------------------------------------------------' |
In the next frame, since some is defined to be a dependent product we extract a pair consisting of an element of the integers, y-x, and a proof, e8, that the proposition is true for this element. This corresponds to the desired meaning of some.
,------------------------------------------------------------, |EDIT THM thm | |------------------------------------------------------------| |* top 1 2 2 1 (* e7 extracted *) | |1...3. | |4. r:~(x=y in int) | |>> some z:int.~(z=0 in int)#(x+z=y in int) | | | |BY intro y-x (* ext <y-x,e8> *) | | | |1* 1...4. | | >> y-x in (int) | | | |2* 1...4. | | >> ((y-x=0 in int)->void)#(x+y-x=y in int) (* ext e8 *)| | | |3* 1...4. | | 5. z:(int) | | >> (~(z=0 in int)#(x+z=y in int)) in U1 | '------------------------------------------------------------' |
The product intro produces a pair consisting of proofs of the two subgoals. Although the proof is not shown here, subgoal 2 can be seen to follow trivially by arith.
,------------------------------------------------------------, |EDIT THM thm | |------------------------------------------------------------| |* top 1 2 2 1 2 (* e8 extracted *) | |1...3. | |4. r:~(x=y in int) | |>> ((y-x=0 in int)->void)#(x+y-x=y in int) (* ext <e9,e10>*)| | | |BY intro | | | |1* 1...4. | | >> (y-x=0 in int)->void (* ext e9 *) | | | |2* 1...4. | | >> x+y-x=y in int (* ext e10==axiom (follows by arith)*)| '------------------------------------------------------------' |
In the next frame we see that
hypotheses 4 and 5 contradict each other. The system somewhat
arbitrarily extracts (![]() v0.any(v0))(r(axiom))
from this (we could extract anything
we desired from a contradiction).
v0.any(v0))(r(axiom))
from this (we could extract anything
we desired from a contradiction).
,------------------------------------------------------------, |EDIT THM thm | |------------------------------------------------------------| |* top 1 2 2 1 2 1 (* e9 extracted *) | |1...3. | |4. r:~(x=y in int) | |>> (y-x=0 in int)->void | | | |BY intro new f (* ext \f.e11 *) | | | |1* 1...4. | | 5. f:y-x=0 in int | | >> void (* ext e11==(\v0.any(v0))(r(axiom)) | | (from a contradiction)*)| | | |2* 1...4. | | >> (y-x=0 in int) in U1 | '------------------------------------------------------------' |
We could now have the following session with the evaluator. What follows has additional white space (spaces and carriage returns) to improve readability.
,------------------------------------------------------------, |P>eval | |E>term_of(thm);; | |\x.\y.(\E.decide(E;l.inl(l); | | r.inr(<y-x,<\f.(\v0.any(v0))(r(axiom)),axiom>>))) | | (int_eq(x;y ;inl(axiom);inr(axiom))) | |E>term_of(thm)(7)(7);; | |inl(axiom) | |E>term_of(thm)(7)(10);; | |inr(<10-7,<\f.(\v0.any(v0))(axiom(axiom)),axiom>>) | |E>let p1 = \x.spread(x;u,v.u);; | |\x.spread(x;u,v.u) | |E>let d = \y.decide(y;u.p1(u);u.p1(u));; | |\y.decide(y;u.p1(u);u.p1(u)) | |E>d(term_of(thm)(7)(10));; | |3 | '------------------------------------------------------------' |
To terminate an eval session type
.

