See title page for important information about this reference
Next: System Description Up: Index Previous: Computation Contents
See title page for important information about this reference
In the study of logic a distinction is made between the logic being studied, the object language, and the language in which the study of the logic is conducted, the metalanguage. In our case the object language is the type theory Nuprl. Thus far in this book we have conducted the discussion of Nuprl using a combination of English and mathematics as an informal metalanguage. In this chapter we introduce a formal metalanguage based upon the ML programming language [Gordon, Milner, & Wadsworth 79].
In ML the various parts of the object language--terms, declarations, proofs and rules--are data types. By defining a formal metalanguage we have made concrete the structure and elements of the object language. We can then write ML programs that manipulate objects of the object language. Thus, for example, we can write a program to return the subterms of a term or one that substitutes a term for a free variable in a term. More importantly, we can write ML functions which search for or transform proofs. We can then use such automated proof techniques and theorem-proving heuristics, tactics, while writing proofs.
A tactic is a function written in ML which partially automates the process of theorem proving in Nuprl. In any logic writing a formal proof is a combination of insightful, interesting steps and tedious ones. Being required to fill in every detail of a proof distracts one's attention from the important parts of the proof and can be quite tiresome. The refinement logic of Nuprl is no exception to this. Given undecidability, we cannot hope to fully automate the theorem-proving process. Ideally, then, we would want the user to enter only the central ideas of a proof and leave the details to be filled in by the system. Tactics offer a mechanism whereby a sketch of a proof supplied by the user can often be completed automatically and many simple proofs can be avoided altogether. Tactics can also be used to automate more difficult patterns of proofs that occur frequently so that essentially the same argument need not be repeated; a tactic for that pattern of proof would be invoked instead. The uses of tactics are many and need not be restricted to the above. There is the potential in the tactic mechanism to express any decision procedure, semidecision procedure or theorem-proving algorithm which is valid in the Nuprl logic. As will be explained in detail below, the implementation of the metalanguage makes sure that all proofs produced by tactics are in fact valid Nuprl proofs. This makes it impossible to write or use a tactic that produces an incorrect proof.6.1
In Nuprl there are predefined tactics that are always available. These include tactics of general use in theorem proving. The user can easily add new tactics that extend the predefined tactics or are specific to the domain of theorems being proved. The next two sections describe two different kinds of tactics: refinement tactics and transformation tactics. This is followed by an introduction to the ML programming language and an explanation of writing simple tactics. Chapter 9 contains a more detailed description of the metalanguage interface and information on writing tactics and examples of more complicated tactics.
A refinement tactic resembles a derived rule of inference. Such a tactic is invoked by typing the name of the tactic where a refinement rule is requested by the proof editor. When the tactic is applied it tries to prove the current goal. There are three possible outcomes from a tactic invocation.
The behavior of a refinement tactic resembles that of a primitive rule of inference or decision procedure (such as arith). However, although refinement tactics are similar to rules of inference, they should not be thought of as fixed rules; within the tactic, for instance, the goal can be examined and different refinements can be applied based upon this analysis. In addition, by using the failure mechanism that is primitive to the ML language a tactic may approach a goal using one technique, find that this leads to a dead-end, backtrack and try another approach. Thus while the result of a tactic may represent just a few primitive refinement steps, the method by which those few steps were arrived at may have required a substantial amount of computation.
Whereas refinement tactics take only goals as arguments and return proofs, transformation tactics take proofs as arguments and return proofs. Transformation tactics can perform much more global analysis and change to proofs than can refinement tactics. These tactics, for instance, can complete or expand an unfinished proof, produce a new proof that is analogous to the given proof and perform various optimizations to the proof such as replacing subproofs with more elegant or concise ones, to name a few of the uses to which they have been put.
A user invokes a transformation tactic by editing the theorem of
interest and traversing the proof until the goal heading the desired
subproof is displayed. The user then types
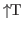 , and Nuprl will prompt
for the name of the transformation tactic which is to be applied. The tactic
is applied to the proof consisting of the current goal and anything that
is below it, that is, any subgoals and proofs below the subgoals. The
transformation tactic, if it succeeds, will return a proof which has the
same goal as the argument proof tree. Unlike those of
refinement tactics, the name
of the transformation tactic is not entered into the proof; the tactic
serves as an operation on proofs, transforming one proof to another.
Upon termination the proof returned may bear little resemblance to the
original proof, except that a transformation tactic cannot change the proof
above the root of the argument, nor can it change the goal of the root of
the subproof. The only exception to this rule is if the subproof is the
whole proof--the tactic was called from the top goal. In this case the
transformation tactic may replace the goal of the proof; thus a
transformation tactic can map one theorem into another. These constraints
are enforced by the implementation and need not be the concern of the
tactic designer or user.
, and Nuprl will prompt
for the name of the transformation tactic which is to be applied. The tactic
is applied to the proof consisting of the current goal and anything that
is below it, that is, any subgoals and proofs below the subgoals. The
transformation tactic, if it succeeds, will return a proof which has the
same goal as the argument proof tree. Unlike those of
refinement tactics, the name
of the transformation tactic is not entered into the proof; the tactic
serves as an operation on proofs, transforming one proof to another.
Upon termination the proof returned may bear little resemblance to the
original proof, except that a transformation tactic cannot change the proof
above the root of the argument, nor can it change the goal of the root of
the subproof. The only exception to this rule is if the subproof is the
whole proof--the tactic was called from the top goal. In this case the
transformation tactic may replace the goal of the proof; thus a
transformation tactic can map one theorem into another. These constraints
are enforced by the implementation and need not be the concern of the
tactic designer or user.
Writing complicated tactics requires a thorough knowledge of the ML programming language [Gordon, Milner, & Wadsworth 79] and the information contained in chapter 9. It is an easy matter, however, to write simple tactics and to combine existing tactics with a minimal subset of ML. ML is a functional programming language with three important characteristics which make it a good language for expressing tactics:
In order to understand the example tactics presented below it is not necessary to know many of the details of ML. The following summarizes some of the more important and less obvious language constructs. Functions in ML are defined as in
let divides x y = ((x/y)*y = x);;
This function has type
int![]() int
int![]() bool; that is,
it maps integers to functions from integers to boolean values. There is
also an explicit abstraction operator,
bool; that is,
it maps integers to functions from integers to boolean values. There is
also an explicit abstraction operator,
![]() , which stands for the more
conventional
, which stands for the more
conventional ![]() . The previous function
could have been defined as
. The previous function
could have been defined as
let divides = \ x . \ y . ((x/y)*y = x);;
Exceptions are raised using the expression
``fail'' and handled (caught) using ``?''. The result of evaluating exp1?exp2 is the
result of evaluating exp1 unless a failure is encountered, in
which case it is the result of evaluating exp2.
For example, the following function returns false if ![]() .
.
let divides x y = (if y = 0 then fail
else (y*(x/y)=x)
) ? false;;
In fact, because dividing by ![]() causes a failure, we could define the same
function with
causes a failure, we could define the same
function with
let divides x y = (y*(x/y)=x)?false;;
From Nuprl the user can request that ML be run interactively by
entering the command ml in the command window.
Nuprl will respond with a M>
prompt in the command window. Any input typed after this prompt is
processed by ML. This facility allows for the examination of variables
and constants in ML and for the tracing, definition and debugging of
tactics. The user leaves the interactive ML mode by typing
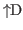 .
.
Although definitions can be entered interactively using this mode, the definitions entered are only temporary. Once the current Nuprl session has been concluded, any changes to the ML state disappear. If more permanent definitions are desired an ML object can be created and edited using the text-editing facilities of Nuprl, and the ML commands in this ML object can be evaluated by ML. To do this a library object of type ``ML'' is created and then edited in Nuprl. Once complete this ML object can be checked, during which process the commands of the ML object are evaluated sequentially by ML. If there are no errors in the object it is marked as good, and any changes in the ML state implicit in the commands will remain in effect throughout the remainder of the Nuprl session. Should an error be encountered while evaluating the ML object an error message will be displayed, and evaluation of the ML object will be discontinued. Any error-free commands that preceded the one with an error will have been evaluated with any changes in state remaining in effect. The user may then view the ML object, make the necessary corrections and recheck it. The commands in an ML object will also be evaluated when it is loaded or restored to the library.
We now examine how some simple tactics are written.
One should think of tactics as mappings from proofs to proofs which may take
additional arguments.
The simplest tactics are formed using the ML
function
refine_using_prl_rule.
This function takes two arguments, a token (the ML equivalent of a string)
and a proof. The token is parsed as a rule, and then the goal of the proof
is refined by this rule. Conceptually the result is a proof with
the top goal refined by the rule indicated by the token and with
the appropriate
subgoals for this refinement. Thus refine_using_prl_rule is a procedural embodiment
of the primitive refinement rules of Nuprl. The function refine_using_prl_rule is
an example of a tactic.
Atomic refinement steps and existing tactics may be combined using a combining form called a tactical. For example, the following tactic refines a goal by intro; then, each of the resultant subgoals is again refined by intro. To each of the subgoals of this the predefined tactic immediate is applied.
let two_intro proof =
(refine_using_prl_rule `intro` THEN
refine_using_prl_rule `intro` THEN
immediate) proof;;
The tactical THEN is an infix operator; it takes two tactics and produces a new tactic. When applied to a proof this new tactic applies the tactic on the left-hand side of the THEN and then, to each of the subgoals resulting from the left-hand tactic, the right-hand tactic. Note that two_intro will only work if it makes sense to perform two levels of introductions. For example, if the tactic is applied to a dependent product (where an intro rule requires an object of the left type) the refinement will fail, causing the tactic to fail.
In addition to THEN, two other tacticals are of general usefulness: REPEAT and ORELSE . The tactical REPEAT will repeatedly apply a tactic until the tactic fails (or fails to do anything). That is, the tactic is applied to the argument proof, and then to the children produced by tactics, and so on. The REPEAT tactical will catch all failures of the argument tactic and can not generate a failure. For example,
let intros = REPEAT (refine_using_prl_rule `intro`);;
will perform (simple) introduction until it no longer applies. The ORELSE tactical takes two tactics as arguments and produces a tactic that applies the -hand tactic to a proof and, if that tactic fails, the right-hand tactic. The following tactic performs all simple introductions and eliminations which are possible.
let goal_simplify =
REPEAT ((refine_using_prl_rule `intro`)
ORELSE (refine_using_prl_rule `elim`));;
Using refine_using_prl_rule, the four tacticals given here and the predefined tactics, many useful tactics can be written. We hope that tactics are easy enough to write and convenient enough to use that the user will be encouraged to experiment with them. In particular, we hope that the user will write tactics for any aspect of theorem proving that is repetitious, stylized or routine.
The power and flexibility of the tactic mechanism go well beyond these simple examples. In chapter 9 we continue the discussion begun here.
set_auto_tactic `transform_tac`;;
This code could be used either in an ML interactive window or placed
in an ML object (and checked). To see what auto_tactic is
currently set to, type
show_auto_tactic ();;
in the ML interactive window.
In general, an auto_tactic should either completely prove a subgoal or leave it unchanged. To ensure this the COMPLETE tactical can be applied to the intended tactic. This tactical changes the argument tactic so that partial results (i.e., those that still have unproved subgoals) are turned into failure. For example, to use transform_tac as the auto-tactic and to make it so that partial results are not used, use the command
set_auto_tactic `COMPLETE transform_tac`;;
To set auto_tactic to
a refinement tactic immediate where partial results are not
used, use the following:
set_auto_tactic `COMPLETE
(refine (tactic \`immediate\`))`;;
This is the default setting of auto_tactic. When the auto-tactic
fails the failure is not reported; rather, the subgoal is just unchanged. By
watching the status characters on subgoals one can tell which have been
proved by the auto-tactic and which still need to be proved.
The auto-tactic is applied to subgoals of primitive refinements only when a proof is being edited. When performing a library load or when using a tactic while editing a proof, the auto-tactic is inhibited.