
The Book
Implementing Mathematics with The Nuprl Proof Development System
See title page for important information about this reference
Next: Computation Up: Index Previous: The Terminal Contents
- Structure of Proofs
- Commands Needed for Proofs
- Examples from Introductory Logic
- Example from Elementary Number Theory
Proofs
This chapter contains an informal introduction to Nuprl proofs. It describes the structure of proofs, shows how to use the refinement editor to move around in and add to proofs, and gives enough description and examples of rule usage to enable the reader to prove theorems of his own. Examples are drawn from logic (section 4.3) and elementary number theory (section 4.4). The reader may at times wish to refer to the complete presentation of the rules; this is contained in chapter 8.
Structure of Proofs
A proof in Nuprl may be thought of as a tree. Associated with each node of the tree is a sequent and, if the node is not a leaf, a rule. A sequent is in turn composed of a numbered list of hypotheses and a goal. The children of a node are uniquely determined by the sequent and rule of that node. If no rule is present, or if the rule is incorrect or not applicable, the node has no children; otherwise, the children correspond to the subgoals generated by the application of the rule to the sequent. Note the departure from conventional usage; a proof need not be complete.
The following example from a Nuprl session was obtained by using the command view example to create a window for the theorem object example and then using the refinement editor, or red for short, to navigate through the proof tree.
,-------------------------------------, |EDIT THM example | |-------------------------------------| |# top 1 1 | |1. x:int | |2. y:int | |>> z:int->(x*(y+z)=x*y+x*z in int) | | | |BY intro | | | |1# 1. x:int | | 2. y:int | | 3. z:int | | >> (x*(y+z)=x*y+x*z in int) | | | |2# 1. x:int | | 2. y:int | | >> int in U1 | '-------------------------------------' |
Displayed in the window above is the sequent to be proven, or main goal, associated with the current node, the rule of the node (preceded by BY), and the sequents corresponding to the two children of the node. This is the way that the system displays a proof tree in a theorem window; it shows a sequent, the rule applied to it (if any), and the immediate subgoals. The location of the node in the tree is given by the header, top 1 1 in this case; this means that the node is the first child of the first child of the root of the proof tree. The sign ``#'' indicates that the status of the subproof is incomplete. Other possible statuses are: ``-'' for bad, meaning that some descendant (leaf) has an incorrect rule application, or that the main goal was not acceptable; ``?'' for raw, which is the status of the proof before the main goal has been parsed; and ``*'' for complete, which indicates that the subproof has been finished.
One usually visualizes a tree as having its root at the top (or bottom) with the branches going downward (upward). In Nuprl, however, a proof tree should be viewed as lying on its side, with the root at the left and with the first child of a given node being at the same height as its parent, and having its siblings below it. Keeping this in mind will make the commands for moving around in proof trees easier to remember.
Commands Needed for Proofs
In the preceding chapter we described how to create theorem objects and how to enter the main goal of such an object; in this section we will talk about the Nuprl commands for viewing and changing proof trees. One builds proofs of theorems using red, the refinement editor. Red is a syntax-directed and rule-driven editor; the proof is developed by specifying instances of rules, such as elim and arith, and the editor ensures that the rule instances are appropriate and calculates the new subgoals. The remainder of this section is a tutorial which develops most of the proof of4.1
>> All x,y:int.Some z:int.
(x<y => z=0 in int) & (~x<y => z=1 in int)
Starting in the command window, type
create t thm top; this command creates the
theorem object and places it in the library.
Now type ml. This activates the ML subsystem;
Nuprl indicates this by giving the prompt ML>.
Type ``set_auto_tactic `COMPLETE immediate`;;'' (note
that the quotes are back quotes) and then hit RETURN.
This has
Nuprl show the steps of any proof that it automatically constructs
using the auto-tactic immediate,
an ML program which performs simple reasoning automatically.
The ML subsystem will be discussed later.
Now return to the command mode by typing
 and
type view t to bring up the window:
and
type view t to bring up the window:
,----------------------------------------, |EDIT THM t | |----------------------------------------| |? top | |<main proof goal> | '----------------------------------------' |
As described in the preceding chapter, enter the main goal; this will result in a window that looks like the following.
,----------------------------------------------------, |EDIT THM t | |----------------------------------------------------| |# top | |>> All x,y:int.Some z:int. | | x<y => (z=0 in int) & ~x<y => (z=1 in int) | | | |BY <refinement rule> | '----------------------------------------------------' |
Note the status; it indicates that the main goal has been successfully
parsed and that the proof can proceed. Also note that the statement of the
theorem now appears in the library window.
Now, the first step of the proof will be to apply
an introduction rule. Since
a universally quantified formula is, by definition, a dependent function
type, the function-introduction rule is required.
It suffices, however, to enter intro as the rule; the system
will determine from the context exactly which type of introduction
is to be applied.
The rule is entered into an edit window, which can be
brought up in two ways. The first way is to type LONG  in order to move the cursor
from the main goal
to ``BY <refinement rule>'' and to then type SEL#8438#>SEL}. The
other way is to position the mouse pointer over ``BY
<refinement rule>'' and then do a mouse SEL,
i.e., a left-click
on the mouse.4.2The system displays the following windows.
in order to move the cursor
from the main goal
to ``BY <refinement rule>'' and to then type SEL#8438#>SEL}. The
other way is to position the mouse pointer over ``BY
<refinement rule>'' and then do a mouse SEL,
i.e., a left-click
on the mouse.4.2The system displays the following windows.
,-------------------------------,--------------, |EDIT THM t |EDIT rule of t| |-------------------------------|--------------| |# top | _ | |>> All x,y:int.Some z:int. | | | x<y => (z=0 in int) & | | | ~x<y => (z=1 in int) | | | | | |BY <refinement rule> | | '-------------------------------'--------------' |
Now type the rule name intro, finishing with a
. In general, a
causes the entered text to
be processed and, unless certain errors have occurred, removes the
rule window. If the first word of the text was a rule name,
then the text which follows, if any, is checked to make sure that it is
appropriate to the rule, and if it is, the rule is applied and
the resulting subgoals, if any, are displayed.
The proof window is now:
,------------------------------------------------------, |EDIT THM t | |------------------------------------------------------| |# top | |>> All x,y:int.Some z:int. | | x<y => (z=0 in int) & ~x<y => (z=1 in int) | | | |BY intro | | | |1# 1. x:(int) | | >> (All y:int.Some z:int. | | x<y => (z=0 in int) & ~x<y => (z=1 in int)) | | | |2* >> (int) in U1 | | | '------------------------------------------------------' |
Nuprl has generated the two subgoals specified by the
function-introduction rule.
Now try moving the cursor around
using LONG  and LONG , and note that
it stops at the four major entries of the window. If
a proof window is not big enough to display all the subgoals,
moving the cursor down will force the window to
be scrolled. Note that the status of subgoal 2 above is
``complete''.
This indicates that the auto-tactic
has completely
proven the second subgoal.
Now position the cursor over the first subgoal
and type
and LONG , and note that
it stops at the four major entries of the window. If
a proof window is not big enough to display all the subgoals,
moving the cursor down will force the window to
be scrolled. Note that the status of subgoal 2 above is
``complete''.
This indicates that the auto-tactic
has completely
proven the second subgoal.
Now position the cursor over the first subgoal
and type ![]() 4.3,
or position the mouse pointer over it and
right-click; either action has the effect
of moving the
theorem window down the proof tree to the indicated subgoal.
Alternatively, one may
type LONG
4.3,
or position the mouse pointer over it and
right-click; either action has the effect
of moving the
theorem window down the proof tree to the indicated subgoal.
Alternatively, one may
type LONG ![]() ; this will always
move the window to
the next (in an order to be described later)
unproved leaf of the proof tree.
The window should now look like:
; this will always
move the window to
the next (in an order to be described later)
unproved leaf of the proof tree.
The window should now look like:
,--------------------------------------------------------, |EDIT THM t | |--------------------------------------------------------| |# top 1 | |1. x:(int) | |>> (All y:int.Some z:int. | | x<y => (z=0 in int) & ~x<y => (z=1 in int)) | | | |BY <refinement rule> | '--------------------------------------------------------' |
To strip off another quantifier, proceed as before
(i.e., type LONG SEL or position
the mouse pointer and left-click, then enter
the rule intro followed by
).
Move to the first of the subgoals by typing
LONG ![]() . The current goal is now:
. The current goal is now:
,--------------------------------------------------------, |EDIT THM t | |--------------------------------------------------------| |# top 1 1 | |1. x:(int) | |2. y:(int) | |>> (Some z:int. | | x<y => (z=0 in int) & ~x<y => (z=1 in int)) | | | |BY <refinement rule> | '--------------------------------------------------------' |
Using an introduction rule here would require that a value for z be supplied. Since the choice of that value depends on whether or not x<y, a case analysis is required. Enter the following as the rule:
seq x<y | ~x<y
In general, this rule, called the sequence rule, introduces a new fact into the proof. The window below shows the two new subgoals; one is to prove the new fact, and the other is to prove the previous goal assuming the new fact.
,---------------------------------------------------------, |EDIT THM t | |---------------------------------------------------------| |# top 1 1 | |1. x:(int) | |2. y:(int) | |>> (Some z:int. | | x<y => (z=0 in int) & ~x<y => (z=1 in int)) | | | |BY seq x<y | ~x<y | | | |1* 1. x:(int) | | 2. y:(int) | | >> x<y | ~x<y | | | |2# 1. x:(int) | | 2. y:(int) | | 3. x<y | ~x<y | | >> (Some z:int. | | x<y => (z=0 in int) & ~x<y => (z=1 in int)) | '---------------------------------------------------------' |
Note that the auto-tactic has proven
the first subgoal.
To see the proof it constructed, move the
window to the first subgoal (LONG LONG
![]() ).
).
,---------------------------------------------------------, |EDIT THM t | |---------------------------------------------------------| |* top 1 1 1 | |1. x:(int) | |2. y:(int) | |>> x<y | ~x<y | | | |BY arith at U1 | | | |1* 1. x:(int) | | 2. y:(int) | | >> x in int | | | |2* 1. x:(int) | | 2. y:(int) | | >> y in int | '---------------------------------------------------------' |
The auto-tactic applied the arith rule
to the subgoal and then proved the
subgoals (using intro). Now go back
to the previous node (i.e., the parent of the current one)
by typing  , or by positioning the
mouse pointer over the main goal of the window and
right-clicking, and proceed to the second subgoal of that node.
The window now becomes:
, or by positioning the
mouse pointer over the main goal of the window and
right-clicking, and proceed to the second subgoal of that node.
The window now becomes:
,---------------------------------------------------------, |EDIT THM t | |---------------------------------------------------------| |# top 1 1 2 | |1. x:(int) | |2. y:(int) | |3. x<y | ~x<y | |>> (Some z:int. | | x<y => (z=0 in int) & ~x<y => (z=1 in int)) | | | |BY <refinement rule> | '---------------------------------------------------------' |
A case analysis on hypothesis 3 above is now required; this is done by entering the rule elim 3.
,---------------------------------------------------------, |EDIT THM t | |---------------------------------------------------------| |# top 1 1 2 | |1. x:(int) | |2. y:(int) | |3. x<y | ~x<y | |>> (Some z:int. | | x<y => (z=0 in int) & ~x<y => (z=1 in int)) | | | |BY elim 3 | | | |1# 1. x:(int) | | 2. y:(int) | | 3. x<y | ~x<y | | 4. x<y | | >> (Some z:int. | | x<y => (z=0 in int) & ~x<y => (z=1 in int)) | | | |2# 1. x:(int) | | 2. y:(int) | | 3. x<y | ~x<y | | 4. ~x<y | | >> (Some z:int. | | x<y => (z=0 in int) & ~x<y => (z=1 in int)) | '---------------------------------------------------------' |
Note
the pattern of rule usage--to break down the conclusion
of the goal we use intro, and to break down a
hypothesis we use elim.
We continue by proving the first subgoal. The second,
which is very similar, is left to the reader.
Type LONG ![]() to get:
to get:
,---------------------------------------------------------, |EDIT THM t | |---------------------------------------------------------| |# top 1 1 2 1 | |1. x:(int) | |2. y:(int) | |3. x<y | ~x<y | |4. x<y | |>> (Some z:int. | | x<y => (z=0 in int) & ~x<y => (z=1 in int)) | | | |BY <refinement rule> | '---------------------------------------------------------' |
It is now possible to specify a value for z, since x<y is a hypothesis. Entering ``intro 0'' as the rule causes z to be instantiated with 0:
,---------------------------------------------------------, |EDIT THM t | |---------------------------------------------------------| |* top 1 1 2 1 | |1. x:(int) | |2. y:(int) | |3. x<y | ~x<y | |4. x<y | |>> (Some z:int. | | x<y => (z=0 in int) & ~x<y => (z=1 in int)) | | | |BY intro 0 | | | |1* 1. x:(int) | | 2. y:(int) | | 3. x<y | ~x<y | | 4. x<y | | >> 0 in (int) | | | |2* 1. x:(int) | | 2. y:(int) | | 3. x<y | ~x<y | | 4. x<y | | >> ((x<y )->(0=0 in int))#((~x<y ))->(0=1 in int) | | | |3* 1. x:(int) | | 2. y:(int) | | 3. x<y | ~x<y | | 4. x<y | | 5. z:(int) | | >> (x<y => (z=0 in int) & ~x<y => (z=1 in int)) in U1 | '---------------------------------------------------------' |
The auto-tactic now finishes the proof of this subgoal.
The rest of the proof is left as an exercise. (Use LONG ![]() to
get to the remaining unproved subgoal.)
to
get to the remaining unproved subgoal.)
Examples from Introductory Logic
Constructive Propositional Logic
Many people have seen formal proofs only during courses
in logic. Most such courses begin with rules in which
the propositional connectives ![]() and
and ![]() correspond to
the natural language connectives ``and'',``or'',``not'' and ``implies'',
respectively. If the nature of propositions is left
unanalyzed except for their propositional structure, and if
the unanalyzed parts are denoted by variables such as
correspond to
the natural language connectives ``and'',``or'',``not'' and ``implies'',
respectively. If the nature of propositions is left
unanalyzed except for their propositional structure, and if
the unanalyzed parts are denoted by variables such as ![]() ,
, ![]() and
and ![]() ,
then the resulting forms are called
propositional formulas.
For example,
,
then the resulting forms are called
propositional formulas.
For example,
![]() is an instance of a propositional formula.
is an instance of a propositional formula.
Let us take a propositional formula which we recognize to be true and
analyze why we believe it. We will then
translate the argument into Nuprl. Consider
the formula
![]() .
We argue for its truth in the following fashion.
If we assume
.
We argue for its truth in the following fashion.
If we assume
![]() then we
need to show
then we
need to show
![]() .
Supposing
.
Supposing
![]() is also
true, we need to show
is also
true, we need to show
![]() ;
that is, we must
show that
;
that is, we must
show that ![]() is true if
is true if ![]() is. Therefore assume
is. Therefore assume ![]() is true.
Now we know
is true.
Now we know
![]() ,
so we can consider two cases;
if we establish the truth of
,
so we can consider two cases;
if we establish the truth of ![]() in each case then we have
finished the proof.
In the first case, where
in each case then we have
finished the proof.
In the first case, where ![]() is true, we are done immediately.
If
is true, we are done immediately.
If ![]() is true, then because
is true, then because
![]() holds we know that
holds we know that ![]() is true, for
that is the meaning of
implication.
Therefore, both
is true, for
that is the meaning of
implication.
Therefore, both ![]() and
and ![]() follow from our assumptions.
This, of course, is a contradiction, and since
from a contradiction we can derive anything,
follow from our assumptions.
This, of course, is a contradiction, and since
from a contradiction we can derive anything,
![]() again is true.
This finishes the argument.
again is true.
This finishes the argument.
To formalize this argument we use the definitions
given in chapter 3 of the constructive propositional connectives
and of all.
We also recognize that to say ![]() and
and
![]() are arbitrary propositions can be taken to mean that they are
arbitrary members of the universe
are arbitrary propositions can be taken to mean that they are
arbitrary members of the universe ![]() .4.4A reasonable formalization of the assertion to be proved, then,
is
.4.4A reasonable formalization of the assertion to be proved, then,
is
all P:U1. all Q:U1. (P|~P) => (~P=>~Q) => (Q=>P).
Following are a few snapshots from a session in which this theorem is proved. Note the similarity between the steps of the formal proof and the steps of the informal proof given above. In the first two windows below, we see the use of the intro rule as the formal analogue of the ``assume'' or ``suppose'' of the informal argument.
,--------------------------------------, |EDIT THM prop1 | |--------------------------------------| |# top 1 | |1. P:(U1) | |>> (all Q:U1. | | (P|~P)=>(~P=>~Q)=>(Q=>P)) | | | |BY intro at U2 | | | |1# 1. P:(U1) | | 2. Q:(U1) | | >> ( (P|~P)=>(~P=>~Q)=>(Q=>P) ) | | | |2* 1. P:(U1) | | >> (U1) in U2 | '--------------------------------------' |
,--------------------------------------, |EDIT THM prop1 | |--------------------------------------| |# top 1 1 1 | |1. P:(U1) | |2. Q:(U1) | |3. (P|~P) | |>> (~P=>~Q)=>(Q=>P) | | | |BY intro at U1 | | | |1# 1. P:(U1) | | 2. Q:(U1) | | 3. (P|~P) | | 4. (~P=>~Q) | | >> (Q=>P) | | | |2* 1. P:(U1) | | 2. Q:(U1) | | 3. (P|~P) | | >> (~P=>~Q) in U1 | '--------------------------------------' |
In the main goal of the next window is the result of five consecutive intros. The step shown below uses elim to do the case analysis of the informal argument.
,----------------------------------------------, |EDIT THM prop1 | |----------------------------------------------| |# top 1 1 1 1 1 | |1. P:(U1) | |2. Q:(U1) | |3. (P|~P) | |4. (~P=>~Q) | |5. Q | |>> P | | | |BY elim 3 | | | |1* 1. P:(U1) | | 2. Q:(U1) | | 3. (P|~P) | | 4. (~P=>~Q) | | 5. Q | | 6. P | | >> P | | | |2# 1. P:(U1) | | 2. Q:(U1) | | 3. (P|~P) | | 4. (~P=>~Q) | | 5. Q | | 6. ~P | | >> P | '----------------------------------------------' |
In the main goal of the next window we see that the conclusion follows from hypotheses 4, 5 and 6. To use hypothesis 4 we elim it.
,---------------------------,--------------------------, |EDIT THM prop1 |EDIT rule of prop1 | |---------------------------|--------------------------| |# top 1 1 1 1 1 2 |elim 4 | |1. P:(U1) | | |2. Q:(U1) | | |3. (P|~P) | | |4. (~P=>~Q) | | |5. Q | | |6. ~P | | |>> P '--------------------------' | | |BY <refinement rule> | '-----------------------------------------------' |
Nuprl will then require us to prove ~P, which is trivial since it is a hypothesis, and then to prove P given the new hypothesis ~Q, which is also trivial, since we will have two contradictory hypotheses. The auto-tactic will handle both of these subgoals. This completes the proof.
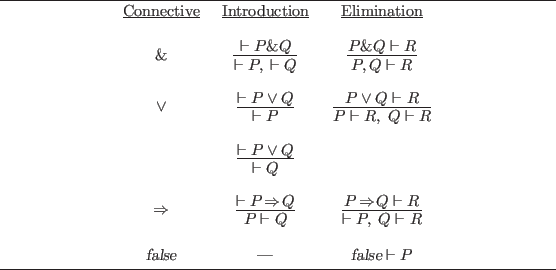
The preceding proof gave a few examples of the application of intro and elim rules to propositional formulas. A more complete account is given in figure 4.1, which shows a set of rules for the constructive propositional calculus in a format suitable to a refinement logic, with the premises (subgoals) below the conclusion (goal). If a goal has the form of one of the goals in the table, then specifying intro or elim as the Nuprl rule will generate the subgoals shown with the exception that => intro will have a second subgoal, P in U1, which will usually be proved by the auto-tactic. The hypotheses shown in the goals of the elim rules will in general be surrounded by other hypotheses, and in all of the rules the entire hypothesis list is copied to the subgoals with any new hypotheses added to the end. Recall that ~P is really P => false, so rules dealing with negation can be derived from the given rules.
Classical Propositional Logic
As we saw in chapter 3, the operators associated with classical logic are easily defined in Nuprl. Now we will see how to prove a typical fact about them. The most characteristic fact about the classical operators is the ``law of the excluded middle,'' which says that for every propositionThe next window shows the hypotheses and subgoals after introducing the arbitrary propositional variable.
,------------------------------------------, |EDIT THM t2 | |------------------------------------------| |# top | |>> all P:U1. P vel ~P | | | |BY intro at U2 | | | |1# 1. P:(U1) | | >> (P vel ~P) | | | |2* >> (U1) in U2 | '------------------------------------------' |
Next we deal with the first subgoal. (The system has dispatched the second one.) Since P vel ~P is defined as a negation, and since negation is defined to be an implication, we prove it via an introduction rule. This results in the two subgoals shown below.
,---------------------------------------, |EDIT THM t2 | |---------------------------------------| |# top 1 | |1. P:(U1) | |>> (P vel ~P) | | | |BY intro at U1 | | | |1# 1. P:(U1) | | 2. ~P&~~P | | >> void | | | |2* 1. P:(U1) | | >> ~P&~~P in U1 | '---------------------------------------' |
The system has proven the second subgoal here. We handle the first subgoal by first breaking down the conjunction in the hypothesis list.
,-----------------------------------------, |EDIT THM t2 | |-----------------------------------------| |# top 1 1 | |1. P:(U1) | |2. ~P&~~P | |>> void | | | |BY elim 2 | | | |1# 1. P:(U1) | | 2. ~P&~~P | | 3. ~P | | 4. ~~P | | >> void | '-----------------------------------------' |
Now we recognize that ~~P is just ~P=>void, so if we eliminate hypothesis 4 the proof will be complete. The result of this command is displayed in the next snapshot.
,-------------------------------------------, |EDIT THM t2 | |-------------------------------------------| |* top 1 1 1 | |1. P:(U1) | |2. ~P&~~P | |3. ~P | |4. ~~P | |>> void | | | |BY elim 4 | | | |1* 1. P:(U1) | | 2. ~P&~~P | | 3. ~P | | 4. ~~P | | >> ~P | | | |2* 1. P:(U1) | | 2. ~P&~~P | | 3. ~P | | 4. ~~P | | 5. void | | >> void | '-------------------------------------------' |
Predicate Logic
Beyond propositional calculus lies an analysis of phrases such as ``for all'', ``for every'', ``there exists'' and ``there is''. As we saw in chapter 3, in Nuprl we treat these phrases as operations on propositional functions. Thus the sentence ``for every integerOnce we have seen how to express arbitrary propositions, we can state all the formulas of the predicate calculus over an arbitrary domain or over an arbitrary nonempty domain as is common in classical logic textbooks. Chapter 3 gave several examples of these statements; we now show how to prove one of them. The snapshots below should be almost self-explanatory, so little further comment will be given.
,----------------------,--------------------------------------, |EDIT THM t3 |EDIT main goal of t3 | |----------------------|--------------------------------------| |? top |>>all A:U1.all P:A->A->U1. | |<main proof goal> | some y:A.all x:A.P(x)(y) => | | | all x:A.some y:A.P(x)(y) | | '--------------------------------------' | | '-------------------------------------------------------------' |
,-------------------------------------------------------, |EDIT THM t3 | |-------------------------------------------------------| |# top 1 1 | |1. A:(U1) | |2. P:(A->A->U1) | |>> some y:A.all x:A.P(x)(y) => all x:A.some y:A.P(x)(y)| | | |BY intro at U1 | | | |1# 1. A:(U1) | | 2. P:(A->A->U1) | | 3. some y:A.all x:A.P(x)(y) | | >> all x:A.some y:A.P(x)(y) | | | |2# 1. A:(U1) | | 2. P:(A->A->U1) | | >> some y:A.all x:A.P(x)(y) in U1 | '-------------------------------------------------------' |
,--------------------------------------,-----------------, |EDIT THM t3 |EDIT rule of t3 | |--------------------------------------|-----------------| |# top 1 1 1 1 |elim 3 | |1. A:(U1) | | |2. P:(A->A->U1) | | |3. some y:A.all x:A.P(x)(y) | | |4. x:(A) | | |>> (some y:A.P(x)(y)) | | | | | |BY <refinement rule> '-----------------| | | '--------------------------------------------------------' |
Since some ![]() :
:![]() .
.![]() is defined to be a
dependent product, an inhabitant of the
third hypothesis above is a pair.
The next elimination step thus requires two new variables, y0
and h in this case,
which will each contain a component of the pair.
is defined to be a
dependent product, an inhabitant of the
third hypothesis above is a pair.
The next elimination step thus requires two new variables, y0
and h in this case,
which will each contain a component of the pair.
,------------------------------------------------, |EDIT THM t3 | |------------------------------------------------| |# top 1 1 1 1 | |1. A:(U1) | |2. P:(A->A->U1) | |3. some y:A.all x:A.P(x)(y) | |4. x:(A) | |>> (some y:A.P(x)(y)) | | | |BY elim 3 new y0, h | | | |1# 1. A:(U1) | | 2. P:(A->A->U1) | | 3. some y:A.all x:A.P(x)(y) | | 4. x:(A) | | 5. y0:(A) | | 6. h:(all x:A.P(x)(y0)) | | >> (some y:A.P(x)(y)) | '------------------------------------------------' |
,------------------------------------------------, |EDIT THM t3 | |------------------------------------------------| |# top 1 1 1 1 1 | |1. A:(U1) | |2. P:(A->A->U1) | |3. some y:A.all x:A.P(x)(y) | |4. x:(A) | |5. y0:(A) | |6. h:(all x:A.P(x)(y0)) | |>> (some y:A.P(x)(y)) | | | |BY intro y0 | | | |1* 1. A:(U1) | | 2. P:(A->A->U1) | | 3. some y:A.all x:A.P(x)(y) | | 4. x:(A) | | 5. y0:(A) | | 6. h:(all x:A.P(x)(y0)) | | >> y0 in (A) | | | |2# 1. A:(U1) | | 2. P:(A->A->U1) | | 3. some y:A.all x:A.P(x)(y) | | 4. x:(A) | | 5. y0:(A) | | 6. h:(all x:A.P(x)(y0)) | | >> (P(x)(y0)) | '------------------------------------------------' |
,-------------------------------------------------, |EDIT THM t3 | |-------------------------------------------------| |* top 1 1 1 1 1 2 | |1. A:(U1) | |2. P:(A->A->U1) | |3. some y:A.all x:A.P(x)(y) | |4. x:(A) | |5. y0:(A) | |6. h:(all x:A.P(x)(y0)) | |>> (P(x)(y0)) | | | |BY elim h on x | | | |1* 1. A:(U1) | | 2. P:(A->A->U1) | | 3. some y:A.all x:A.P(x)(y) | | 4. x:(A) | | 5. y0:(A) | | 6. h:(all x:A.P(x)(y0)) | | >> x in (A) | | | |2* 1. A:(U1) | | 2. P:(A->A->U1) | | 3. some y:A.all x:A.P(x)(y) | | 4. x:(A) | | 5. y0:(A) | | 6. h:(all x:A.P(x)(y0)) | | 7. (P(x)(y0)) | | >> (P(x)(y0)) | '-------------------------------------------------' |
Example from Elementary Number Theory
In chapter 3 simple results about integers were stated; now a simple number-theoretic argument will be developed. Our goal is to prove that every nonnegative integerThe following Nuprl statement poses the computational problem that we want to solve.
>> all x:int. x>=0 => some y:int. y*y <= x < (y+1)*(y+1)
A proof of this statement in Nuprl must be constructive because the constructive connectives and quantifiers defined in chapter 3 are used to state the problem; hence the proof will implicitly contain a method for computing square roots. We will use the proof to define the square root function. Before looking at the formal proof, however, let us consider an informal constructive proof.
We clearly want to proceed by induction, because one
can build the root of ![]() from a root
from a root ![]() of
of ![]() by testing
whether
by testing
whether
![]() If this inequality holds then
If this inequality holds then ![]() is also the root
of
is also the root
of ![]() ; if it does not then
; if it does not then ![]() is the root of
is the root of
![]() . Therefore we
introduce
. Therefore we
introduce ![]() and then perform induction on
and then perform induction on
![]() (the Nuprl rule for this being elim x).
Integer induction generally involves three proof obligations:
one for downward induction, to establish the result for negative
numbers, one for the base case,
(the Nuprl rule for this being elim x).
Integer induction generally involves three proof obligations:
one for downward induction, to establish the result for negative
numbers, one for the base case, ![]() , and one for the upward case of
the positive integers. For this proof the downward case is trivial
because
, and one for the upward case of
the positive integers. For this proof the downward case is trivial
because ![]() is assumed to be nonnegative.
The base case is also trivial
because for
is assumed to be nonnegative.
The base case is also trivial
because for ![]() we must take
we must take ![]() to be
to be ![]() .
We are left with the upward induction
case, for which the induction assumption is
.
We are left with the upward induction
case, for which the induction assumption is
We know
We want to examine this
Once we have ![]() we can do a case
analysis on whether or not
we can do a case
analysis on whether or not
![]() .
We would like to invoke the ``trichotomy'' rule,
.
We would like to invoke the ``trichotomy'' rule,
and then observe that the first case is impossible so that we only need to consider
In the first case y0 is the root and in the last case y0+1 is.
In the snapshots which follow the preceding informal argument is formalized in Nuprl. The first snapshot shows the result of the first introduction rule applied to the statement of the theorem.
,----------------------------------------------------, |EDIT THM root | |----------------------------------------------------| |# top | |>> all x:int. x>=0 => some y:int. y*y<= x <(y+1)* | | (y+1) | | | |BY intro | | | |1# 1. x:(int) | | >> ( x>=0 => some y:int. y*y<= x <(y+1)*(y+1) ) | | | |2* >> (int) in U1 | `----------------------------------------------------' |
The new h part of the rule shown in the next snapshot directs the refinement editor to label the new hypothesis with h. Recall that when x is an integer elim x is the refinement rule for induction.
,----------------------------------------------------, |EDIT THM root | |----------------------------------------------------| |# top 1 | |1. x:(int) | |>> ( x>=0 => some y:int. y*y<= x <(y+1)*(y+1) ) | | | |BY elim x new h | | | |1# 1. x:(int) | | 2. x<0 | | 3. h:( x+1>=0 => some y:int. y*y<= x+1 <(y+1)* | | (y+1)) | | >> ( x>=0 => some y:int. y*y<= x <(y+1)*(y+1) ) | | | |2# 1. x:(int) | | >> ( 0>=0 => some y:int. y*y<= 0 <(y+1)*(y+1) ) | | | |3# 1. x:(int) | | 2. 0<x | | 3. h:( x-1>=0 => some y:int. y*y<= x-1 <(y+1)* | | (y+1)) | | >> ( x>=0 => some y:int. y*y<= x <(y+1)*(y+1) ) | `----------------------------------------------------' |
We now introduce the fact that x-1>=0 in order to use the induction hypothesis.
,----------------------------------------------------, |EDIT THM root | |----------------------------------------------------| |# top 1 3 1 | |1. x:(int) | |2. 0<x | |3. h:( x-1>=0 => some y:int. y*y<= x-1 <(y+1)*(y+1))| |4. (x>=0) | |>> (some y:int. y*y<= x <(y+1)*(y+1)) | | | |BY seq x-1>=0 | | | |1* 1. x:(int) | | 2. 0<x | | 3. h:( x-1>=0 => some y:int. y*y<= x-1 <(y+1)* | | (y+1)) | | 4. (x>=0) | | >> x-1>=0 | | | |2# 1. x:(int) | | 2. 0<x | | 3. h:( x-1>=0 => some y:int. y*y<= x-1 <(y+1)* | | (y+1)) | | 4. (x>=0) | | 5. x-1>=0 | | >> (some y:int. y*y<= x <(y+1)*(y+1)) | `----------------------------------------------------' |
In the next step we want to obtain the consequent of hypothesis 3, the induction hypothesis. Since we know x-1>=0 the first subgoal will be immediate. The interesting part is subgoal 2, in which the consequent is now available. (From now on we will elide some of the hypotheses by substituting ``...'' for them.4.5)
,----------------------------------------------------, |EDIT THM root | |----------------------------------------------------| |# top 1 3 1 2 | |1. x:(int) | |2. 0<x | |3. h:( x-1>=0 => some y:int. y*y<= x-1 <(y+1)*(y+1))| |4. (x>=0) | |5. x-1>=0 | |>> (some y:int. y*y<= x <(y+1)*(y+1)) | | | |BY elim h new r | | | |1* 1...5. | | >> (x-1>=0) | | | |2# 1...5. | | 6. r:(some y:int. y*y<= x-1 <(y+1)*(y+1)) | | >> (some y:int. y*y<= x <(y+1)*(y+1)) | `----------------------------------------------------' |
Now we choose a name, y0, for the witness of the existential quantifier in line 6. As a result we are also required to supply a name for the fact known about y0, namely hh.
,----------------------------------------------------, |EDIT THM root | |----------------------------------------------------| |* top 1 3 1 2 2 | |1. x:(int) | |2. 0<x | |3. h:( x-1>=0 => some y:int. y*y<= x-1 <(y+1)*(y+1))| |4. (x>=0) | |5. x-1>=0 | |6. r:(some y:int. y*y<= x-1 <(y+1)*(y+1)) | |>> (some y:int. y*y<= x <(y+1)*(y+1)) | | | |BY elim r new y0,hh | | | |1# 1...6. | | 7. y0:(int) | | 8. hh:( y0*y0<= x-1 <(y0+1)*(y0+1)) | | 9. r=<y0,hh> in (some y:int. y*y<= x-1 <(y+1)*(y+| | 1)) | | >> (some y:int. y*y<= x <(y+1)*(y+1)) | `----------------------------------------------------' |
Now the sequence rule is used to introduce the formula needed for the case analysis.
,----------------------------------------------------, |EDIT THM root | |----------------------------------------------------| |# top 1 3 1 2 2 1 | |1...7. | |8. hh:( y0*y0<= x-1 <(y0+1)*(y0+1)) | |9. r=<y0,hh> in (some y:int. y*y<= x-1 <(y+1)*(y+1))| |>> (some y:int. y*y<= x <(y+1)*(y+1)) | | | |BY seq (y0+1)*(y0+1)<x | ~(y0+1)*(y0+1)<x | | | |1* 1...7. | | 8. hh:( y0*y0<= x-1 <(y0+1)*(y0+1)) | | 9. r=<y0,hh> in (some y:int. y*y<= x-1 <(y+1)*(y+| | 1)) | | >> (y0+1)*(y0+1)<x | ~(y0+1)*(y0+1)<x | `----------------------------------------------------' |
The contradictory case follows.
,----------------------------------------------------, |EDIT THM root | |----------------------------------------------------| |* top 1 3 1 2 2 1 2 1 1 | |1...9. | |10. (y0+1)*(y0+1)<x | ~(y0+1)*(y0+1)<x | |11. (y0+1)*(y0+1)<x | |12. (y0*y0<= x-1 ) | |13. ( x-1 <(y0+1)*(y0+1)) | |>> (some y:int. y*y<= x <(y+1)*(y+1)) | | | |BY arith at U1 | `----------------------------------------------------' |
Now comes the other part of the trichotomy analysis.
,----------------------------------------------------, |EDIT THM root | |----------------------------------------------------| |# top 1 3 1 2 2 1 2 2 | |1...9. | |10. (y0+1)*(y0+1)<x | ~(y0+1)*(y0+1)<x | |11. ~(y0+1)*(y0+1)<x | |>> (some y:int. y*y<= x <(y+1)*(y+1)) | | | |BY seq ( (y0+1)*(y0+1)=x in int ) | x<(y0+1)*(y0+1) | `----------------------------------------------------' |
Now we conduct a case analysis. Only a few steps of each case are shown.
,----------------------------------------------------, |EDIT THM root | |----------------------------------------------------| |# top 1 3 1 2 2 1 2 2 2 1 | |13. ( (y0+1)*(y0+1)=x in int ) | |>> (some y:int. y*y<= x <(y+1)*(y+1)) | | | |BY intro (y0+1) | | | |1* 1...10. | | 11. ~(y0+1)*(y0+1)<x | | 12. ( (y0+1)*(y0+1)=x in int ) | x<(y0+1)*(y0+1) | | 13. ( (y0+1)*(y0+1)=x in int ) | | >> (y0+1) in (int) | `----------------------------------------------------' |
,----------------------------------------------------, |EDIT THM root | |----------------------------------------------------| |* top 1 3 1 2 2 1 2 2 2 1 2 1 | |1...10. | |11. ~(y0+1)*(y0+1)<x | |12. ( (y0+1)*(y0+1)=x in int ) | x<(y0+1)*(y0+1) | |13. ( (y0+1)*(y0+1)=x in int ) | |>> ((y0+1)*(y0+1)<= x ) | | | |BY arith at U1 | `----------------------------------------------------' |
Now we consider the other case, given by hypothesis 13 above.
,----------------------------------------------------, |EDIT THM root | |----------------------------------------------------| |* top 1 3 1 2 2 1 2 2 2 | | 1...9. | | 10. (y0+1)*(y0+1)<x | ~(y0+1)*(y0+1)<x | | 11. ~(y0+1)*(y0+1)<x | | 12. ( (y0+1)*(y0+1)=x in int ) | x<(y0+1)*(y0+1) | | 13. x<(y0+1)*(y0+1) | | >> (some y:int. y*y<= x <(y+1)*(y+1)) | | | |BY intro y0 | `----------------------------------------------------' |
,----------------------------------------------------, |EDIT THM root | |----------------------------------------------------| |* top 1 3 1 2 2 1 2 2 2 2 2 | |1...11. | |12. ( (y0+1)*(y0+1)=x in int ) | x<(y0+1)*(y0+1) | |13. x<(y0+1)*(y0+1) | |>> ( y0*y0<= x <(y0+1)*(y0+1)) | | | |BY intro | `----------------------------------------------------' |
Assuming that the theorem has been proved and is named root,
the term term_of(root) will
evaluate4.6 to
a function which takes an integer x and
a proof of
x>=0 and produces a proof of some y:int.(...). A proof of
the latter is a pair, the first element of which is
the integer square root of x.
Thus the
definition below of rootf, when instantiated
with a nonnegative integer
as its parameter, will evaluate to the integer square
root of the supplied integer.
The definition uses a defined function 1of which
returns the first element of a pair. Also, we supply
![]() v.v as the proof of x>=0; since by definition
x>=0 is x<0=>void, a proof of it, if it is true,
can be any lambda term.
v.v as the proof of x>=0; since by definition
x>=0 is x<0=>void, a proof of it, if it is true,
can be any lambda term.
rootf(<x:int>) == 1of( term_of(root)(<x>)(\v.v) )
This is a partial function
on int because its domain is a subset of int. It
is a total function from nonnegative integers to integers.
If we want a function which will return an integer value on all integer inputs, then the following theorem describes a reasonable choice.
>> all x:int. some y:int.
(x<0 => y=0 in int) & (x>=0 => y*y<=x<(y+1)*(y+1))
If this theorem is called troot then a
(total) square root function on int can be defined by
sqrt(<x:int>)== 1of(term_of(troot)(x)).
Footnotes
- ... of4.1
- The definitions of the logical connectives, which were presented in the preceding chapter, are used here.
- ... mouse.4.2
- In general, any action involving the cursor and SEL key can also can be done using the mouse pointer and a left-click.
- ...4.3
- Recall that we think of the proof tree as lying on its side.
- ....4.4
- It might seem
natural to be more general and say that
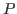 and
and 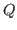 belong to any
belong to any
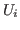 whatsoever. This is something that we will be able to do in Nuprl
shortly, but we do not want to discuss such matters at this point.
whatsoever. This is something that we will be able to do in Nuprl
shortly, but we do not want to discuss such matters at this point.
- ... them.4.5
- Soon the system will allow the user to suppress the display of any hypotheses he is not interested in.
- ...4.6
- Evaluation in Nuprl will be discussed in the next chapter.