
The Book
Implementing Mathematics with The Nuprl Proof Development System
See title page for important information about this reference
Next: Mathematics Libraries Up: Index Previous: The Metalanguage Contents
Building Theories
This chapter is addressed primarily to those who plan to use Nuprl to build a nontrivial collection of theorems. In it we discuss working with proofs, structuring knowledge in a theory, representing common concepts in the Nuprl logic, and dealing with certain recurring problems.
Proofs
Proofs in informal mathematics generally have a linear form; one proceeds by deducing new facts from established ones until the desired result has been reached. Proofs in Nuprl, however, have a structure geared toward top-down development. This means, for example, that facts established earlier in the course of a proof are not immediately available. In this section we discuss this problem and others which arise from the structure of Nuprl proofs.
If in the middle of a proof one discovers that the current subgoal is similar to one proved previously, the pair of tactics mark and copy can be used. As mentioned in the preceding chapter, they are used by running mark as a transformation tactic on the subgoal which is thought to be similar and then running copy as a transformation tactic on the subgoal to be proved. The tactic copy will attempt to reproduce the proof of the marked subgoal, making simple modifications if the subgoals are not identical. Using mark and copy is not, however, a complete solution to the problem; it is often difficult to locate the required subgoal, and it can be time consuming to use the proof editor to get to it even when one has a very good idea of where it is.
Fortunately,
this problem can to a large extent be avoided with
a bit of planning. First, the linear style of informal
mathematics can be approximated using the library
by proving separately, as lemmas,
those things of which it is
anticipated that several uses will be made.
Well-formedness goals, i.e., those of the form
» ![]() in U
in U![]() , are by far the most common
type of duplicated subgoal.10.1 The tactic immediate
can handle a good number of these, but many are
quite nontrivial.10.2Therefore, it is often wise at the outset to
prove the appropriate
well-formedness theorems for
the basic objects of a theory. For example,
if the constructive reals, R, and addition of
real numbers have been defined then the theorems
, are by far the most common
type of duplicated subgoal.10.1 The tactic immediate
can handle a good number of these, but many are
quite nontrivial.10.2Therefore, it is often wise at the outset to
prove the appropriate
well-formedness theorems for
the basic objects of a theory. For example,
if the constructive reals, R, and addition of
real numbers have been defined then the theorems
>> R in U1
>> All x,y:R.(x+y in R)
should be proved. If one is building a reasonably large theory then a much better solution is to define the basic objects of the theory to be extractions from theorems, for then such well-formedness subgoals can be handled automatically. This is discussed in more detail in the next section.
There is no ``thinning'' rule in Nuprl, i.e., a rule which
would allow one to remove hypotheses from a goal. This means
that it can be difficult for a tactic to assemble a
proof in a bottom-up fashion; an already
constructed proof cannot be used to prove a goal
with the same conclusion unless the hypothesis lists
are identical. A solution to this is to arrange things so
that what are constructed bottom-up are tactics, not
proofs. This was the approach taken in the
writing of the term-rewriting package described in chapter 9.
A function which rewrites a term ![]() produces not a proof of
produces not a proof of ![]() =
=![]() in
in ![]() , for some
, for some
![]() ,
, ![]() , but
, but ![]() and a tactic which can be applied to
goals of the form »
and a tactic which can be applied to
goals of the form » ![]() =
=![]() in
in ![]() . This approach
also provides some flexibility with respect to the containing type
. This approach
also provides some flexibility with respect to the containing type
![]() .
.
We conclude this section by making a few points of a more minor nature.
First, if in the middle of a proof one realizes
that a particular unproven fact will be required several times
in the subproof, the sequence rule, seq,
can be used to get
it into the hypothesis list.
If one is reasonably careful in choosing what
lemmas to prove, however, the need for this use
of the sequence rule does not appear to arise too often.
Second, it is a
good idea to
be attentive to the timing of elim's.
Often a considerable amount of work can be saved by doing
them before other branching of the proof occurs. Also,
an elim involves a substitution in the
conclusion; since this substitution is not done in the hypotheses following
the eliminated hypothesis, it may be desirable to do eliminations before
the left part of a function type is moved into the hypothesis list via
an introduction. Third, one should try to arrange things so that
the hypothesis list does not
become unnecessarily large, especially
when writing tactics. For example, if one wants
to use an instantiation of a universally quantified theorem,
using the lemma rule and then doing the appropriate
number of eliminations will give as many extra hypotheses
as there are universal quantifiers to remove; this can badly
clutter up a proof. This can
be avoided by first sequencing in the instantiated form
of the lemma. The first goal will be to prove the instantiated
version, which is done with the lemma rule, and the second
subgoal will have just the desired version of the lemma
added to the hypothesis
list. Finally, when proving a conjunct
![]() &
& ![]() both
both ![]() and
and ![]() need to be proven, but
it might be easier, or necessary, to have
need to be proven, but
it might be easier, or necessary, to have ![]() as a hypothesis
in the proof of
as a hypothesis
in the proof of ![]() . If the
first step in the proof of
. If the
first step in the proof of ![]() &
& ![]() is seq
is seq ![]()
![]() ,
then the nontrivial subgoals will be
»
,
then the nontrivial subgoals will be
» ![]() and
and ![]() »
» ![]() .
.
Definitions
The advantages of the definition mechanism in Nuprl are obvious, and it should be utilized as frequently as possible. By layering definitions finely, i.e., by having the right-hand sides of the definitions of theory objects mention primarily other definitions and not Nuprl code, the meaning will be clear at all stages of a proof. However, unless some care is taken it is easy to build definitions whose denoted text is very large, and this can affect system performance. In practice it has happened on occasion that objects whose display form looked quite innocent caused the system performance to be rather seriously degraded. Fortunately this problem can be avoided.
First, avoid unnecessary formal parameter duplication. For example, the obvious way to define negation of a rational number (which we think of as a pair of integers) is
-<x:Q> == < -fst(<x>), snd(<x>) >
where fst(<x>) and snd(<x>) are the appropriate
selector functions defined in terms of spread.
If we made all the definitions involved in
rational arithmetic in this manner then the size of the
expanded form of an arithmetic expression could be
exponentially larger than the displayed form. To avoid
this we make better use of spread:
-<x:Q> == spread( <x>; u,v. <-u,v>).
Of course, tricks such as the above cannot always be done, and
even without formal parameter duplication defined objects
will eventually be very large.
A general way to handle
the size buildup involves
defining an object to be an extraction
term_of(
THM Q_
>> U1
DEF Q
Q == term_of(Q_)
THM mult_
>> Q -> Q -> Q
DEF mult
<x:Q>*<y:Q> == term_of(mult_)(<x>)(<y>)
Each of the two theorems would have an extraction which was the
appropriate code. For example, the first step of the
proof of mult_ might be
explicit intro
\x. \y. <fst(x)*fst(y), snd(x)*snd(y)>
where fst and snd are projections from pairs
defined using spread.
This method of using extractions is workable because of the direct computation rules. When a variable is declared in a hypothesis list to be of a type which is really an extraction (such as the type Q above), then the actual (canonical) type must be obtained before an elimination of the variable can be done. An application of the direct computation rule will do this, and in fact it is easy to incorporate such computations into tactics so that the ``indirectness'' of the definitions can be made virtually invisible.
It might be useful to have an idea of when
display forms can be maintained. It is rather dismaying
to be proceeding smoothly through a proof and suddenly
come upon an unreadable chunk of raw Nuprl code
resulting from definitions being eliminated. This
doesn't happen too often, but when it does it can make a
proof very difficult. Because definitions are
text macros (i.e., they are not tied to term structure), substitution
can cause definitions to be lost,
leaving only the actual text the definition references denote.
When a term ![]() is substituted for a variable
is substituted for a variable ![]() in a term
in a term
![]() , two different kinds of replacement are done. First, the
usual substitution is done on the term
, two different kinds of replacement are done. First, the
usual substitution is done on the term ![]() . Then a textual
replacement is done, with a result the same as would be
obtained by a user manually replacing in a ted window all
visible occurrences of
. Then a textual
replacement is done, with a result the same as would be
obtained by a user manually replacing in a ted window all
visible occurrences of ![]() , whether free or bound. If the two
resulting terms are not equal (or if the textual replacement did not
even result in a term), then the definition is removed,
leaving just the term which resulted from the usual substitution.
For example, consider substituting x for y
in all x:T. x<y (where all has the usual definition).
The substitution requires
, whether free or bound. If the two
resulting terms are not equal (or if the textual replacement did not
even result in a term), then the definition is removed,
leaving just the term which resulted from the usual substitution.
For example, consider substituting x for y
in all x:T. x<y (where all has the usual definition).
The substitution requires ![]() -conversion; all x's in
the term are renamed x@
-conversion; all x's in
the term are renamed x@![]() , and the substitution results
in x@
, and the substitution results
in x@![]() :T -> x@
:T -> x@![]() <x. The replacement, on the other hand,
results in all x:T. x<x; these two terms are not equal, so
the definition all is not retained and the display form of
the result is the former term.
<x. The replacement, on the other hand,
results in all x:T. x<x; these two terms are not equal, so
the definition all is not retained and the display form of
the result is the former term.
We end this section with a word about debugging definitions. Many of the basic objects of a theory have a computational meaning and so can be executed. Before one starts proving properties of these objects it is a good idea to ``debug'' them, i.e., to use the Nuprl evaluator to test the objects in order to remove trivial errors. In this way one can avoid the frustrating experience of reaching the bottom of a proof and discovering that it cannot be completed because of a mistake in one of the definitions used.
Sets and Quotients
The quotient type provides a powerful abstraction mechanism and puts a user-defined equality into the theory so that the rules for reasoning about equality (the equality and substitution rules and all the intro rules for equality of noncanonical members) can be applied to it. The obverse of this is that if
<x:Q> < <y:Q> in Q ==
fst(<x>)*snd(<y>) < fst(<y>)*snd(<x>).
The difficulty here is that type equality in Nuprl is strong;
two types are equal if they are structurally the same, and
so there are types which have the same members but are not equal.
In particular,
two less-than types can be shown to be equal
only if it can be shown that their corresponding components
are equal as integers.
Therefore, if we could show that the above were a type
then for any pairs of integers <i,j>, <i',j'>, and
<m,n>
such that
<i,j> and <i',j'> are equal as rational numbers, we would have
( i*n < m*j ) = ( i'*n < m*j' ) in U1
. In particular, we would have
i*n = i'*n in int,
which is not always true.
Thus we cannot use the above definition
of less-than over the quotient-type Q.
However, we are only interested
in the truth value of less-than, i.e., whether or
not it is inhabited, and this property is independent
of representatives. In this situation, we squash the
type. Define
||<T:type>|| == {0 in int|<T>}.
This squashes a type in the sense that given a type
Note that squashing does away with any computational content that the
type might have had (this will be discussed further later in
this section). If you are interested in that content and you cannot
reformulate so as to bring out from under the squash operator the part
you are interested in, you cannot use the quotient type and must treat
the equality you want as you would any other defined relation.
More precisely, suppose that ![]() is some quotient type and
is some quotient type and ![]() is some property of members of
is some property of members of ![]() that one wishes to express in Nuprl.
If, as above, one is interested only in the truth value of
that one wishes to express in Nuprl.
If, as above, one is interested only in the truth value of ![]() ,
i.e., whether or not its type representation is inhabited, and if
the truth value respects the equality relation of
,
i.e., whether or not its type representation is inhabited, and if
the truth value respects the equality relation of ![]() , then the squash
operator can be applied. Usually in this case the type resulting
from a direct translation of
, then the squash
operator can be applied. Usually in this case the type resulting
from a direct translation of ![]() according to the propositions-as-types
principle will have at most one member, and that member will be known in
advance (e.g., axiom), so one would lose nothing by squashing.
Often, however,
according to the propositions-as-types
principle will have at most one member, and that member will be known in
advance (e.g., axiom), so one would lose nothing by squashing.
Often, however, ![]() will have some content of interest; for example,
it might involve an assertion of
the existence of some object, and one might wish to construct
a function which takes a member
will have some content of interest; for example,
it might involve an assertion of
the existence of some object, and one might wish to construct
a function which takes a member ![]() of
of ![]() satisfying
satisfying ![]() to the object
whose existence is asserted, but this may not be possible if the
property has been squashed. What one has to do in this case is to
separate
to the object
whose existence is asserted, but this may not be possible if the
property has been squashed. What one has to do in this case is to
separate ![]() into two pieces so that it can be expressed by a type
into two pieces so that it can be expressed by a type ![]() :
:![]() # ||
# ||![]() ||, or equivalently, {
||, or equivalently, {![]() :
:![]() |
|![]() }, where
}, where ![]() represents the computationally interesting part and
represents the computationally interesting part and ![]() represents the
part of which only the truth value is interesting. This requires
that the type
represents the
part of which only the truth value is interesting. This requires
that the type ![]() respect equality in
respect equality in ![]() and
that for any two representatives chosen for
and
that for any two representatives chosen for ![]() the collection
of computationally interesting objects be the same.
the collection
of computationally interesting objects be the same.
We illustrate the points raised above with an example. The usual formulation of the constructive real numbers is as a certain set of sequences of rational numbers with known convergence rates, where two such sequences are considered equal if they are the same in the limit. One crucial property of real numbers is that each one has a rational approximation to within any desired accuracy. Given a particular real number, obtaining such an approximation simply involves picking out an element suitably far along in the sequence, since the convergence rate is known. However, clearly one can have two different but equal real numbers for which this procedure gives two different answers, and in fact it is impossible constructively to come up with approximations in a way which respects equality. Since many computations over the real numbers involve approximations, one cannot bury the property of having a rational approximation under the squash operator. The upshot is that the constructive reals cannot be ``encapsulated'' as a quotient type; one must take the reals to be just the type of rational sequences and treat the equality relation separately. However, one can still use the quotient type to some extent in a situation such as this. For example, in the real number case one can still form the quotient type and use it to express the equality relation. Thus, although hypothetical real numbers will be members of the unquotiented version, one can express equality between reals as equality in the quotient type and so can use the equality rule, etc., to reason about it.
It should not be concluded from the preceding discussion that one should never represent anything with the quotient type. There is a wide class of domains for which the quotient as a device for complete abstraction with respect to equality is a safe choice. This class consists of those domains where the desired equality is such that canonical representatives exist, i.e., where one can prove the existence of a function from the quotient type to its base type which takes equal members of the quotient type to the same member of the equivalence class in the base type. This will allow one to express properties which do not respect equality by having them refer to the canonical representative. An example of a common domain with this property is the rational numbers, where the canonical representative for a fraction is the fraction reduced to lowest terms.
The squash operation defined earlier is just one particular use of the information-hiding capability of the set type. It can also be used to remove from the ``computational part'' of the theorem information whose computational content is uninteresting and which would otherwise reduce the efficiency of the extracted code or information which would make the theorem weaker than one desired. As an example of the first kind of information, we could define the type of integers which are perfect squares two different ways:
n:int # Some m:int. (n=m*m in int)
or
{ n:int | Some m:int. (n=m*m in int) }.
Suppose we had some variable declared in a hypothesis
to be in one of the perfect square types. In each case we could
eliminate it to get an integer which we know to be a
perfect square. In the first case we could do another elimination
to get our hands on the integer whose square is the first integer,
and we could use this square root freely in the proof of the conclusion.
However, this will not be allowed in the second case.
The system will ensure that the proof that the number is
a square is not used in the
term which is built
as the proof of the conclusion. On the other hand, if one
is interested only in the integer which is a perfect square, and
only needs the perfect square property to prove something about
a program which does not need the square root, then the
second version can be used to get
a more efficient extracted object.
As an example of the second kind of information hiding referred to
above, consider the
specification of a function which is to search an array of integers for
a given integer and return an index, where it is known in advance that
the integer occurs in the array. If integer
arrays of length ![]() are represented as
functions from {1..
are represented as
functions from {1..![]() } to the integers, where {1..
} to the integers, where {1..![]() } is
defined to be the appropriate subset of the integers, a
naive translation of the requirements for the search program
into the Nuprl logic might be the
following:
} is
defined to be the appropriate subset of the integers, a
naive translation of the requirements for the search program
into the Nuprl logic might be the
following:
All n:N. All a:{1..n}->int. All k:int.
Some i:{1..n}. a(i)=k in int
=> Some i:{1..n}. a(i)=k in int
This specifies a trivial function which requires as an argument the
answer which it is to produce,
and so it does not capture the meaning of the informal
requirements.
This problem is solved by use of the set type to ``hide''
the proof of the fact that k occurs in the array.
If we make the Nuprl definition
All <x>:<T> where <P>. <P'> ==
<x>: {<x>:<T>|<P>} -> <P'>
then we can give the correct specification as
All n:N. All a:{1..n}->int.
All k:int where ( Some i:{1..n}. a(i)=k in int ) .
Some i:{1..n}. a(i)=k in int
In a proof of this assertion, if one has done intro steps to
remove the universal quantifiers and thus has n,
a and k declared in the hypothesis list, then the type that
k is in is a set type. The only way to get at the information
about k (i.e., that it occurs in the array) is to use the elim
rule on it. However, doing so will cause the desired information
to be hidden (see the set elim rule), and it will not become
unhidden until the proof has proceeded far enough so that the required
function has been completely determined. Thus, the information can be
used only to prove that the constructed function meets the
specification, not to accomplish the construction itself.
The set type should be regarded
primarily as an information-hiding
construct. It cannot be used as a general device for
collecting together all objects (from some type) with a certain property,
as it would in conventional mathematics.
One of the reasons has just been discussed:
if the set type is used to represent a subtype of a given type then
being given a member of the subtype does not involve being given a proof
of its membership; that is, the proof that the member is a member
will be hidden, and in the Nuprl theory this means that information
is irretrievably lost. Another reason is that for ![]() a member of a type
a member of a type ![]() the property of being a member of {
the property of being a member of {![]() :
:![]() |
|![]() } cannot be
expressed unless it is always true. This is because the type
} cannot be
expressed unless it is always true. This is because the type ![]() in
in ![]() is really a short form for
is really a short form for ![]() =
=![]() in
in ![]() ; it
expresses an equality judgement and is well-formed only if
; it
expresses an equality judgement and is well-formed only if ![]() is a
member of
is a
member of ![]() . The problem remains of how to form the type which
represents the power set of a given type. Bishop [Bishop 67] defines
a subset of a given set
. The problem remains of how to form the type which
represents the power set of a given type. Bishop [Bishop 67] defines
a subset of a given set ![]() to be a set
to be a set ![]() together with an injection
together with an injection
![]() from
from ![]() into
into ![]() . If one takes this definition and does the
obvious translation into Nuprl then it turns out that the collection
of such subsets (within some fixed universe U
. If one takes this definition and does the
obvious translation into Nuprl then it turns out that the collection
of such subsets (within some fixed universe U![]() ) of a given type
) of a given type ![]() is equivalent to the function type
is equivalent to the function type ![]() ->U
->U![]() . This latter formulation, where we identify a subset with
the predicate which ``identifies'' the members of the subset, is much
simpler to deal with than Bishop's version. For example, the
proposition that
. This latter formulation, where we identify a subset with
the predicate which ``identifies'' the members of the subset, is much
simpler to deal with than Bishop's version. For example, the
proposition that ![]() (for
(for ![]() in
in ![]() ) is in a subset
) is in a subset ![]() is expressed
just by
is expressed
just by ![]() (
(![]() ); the union of two subsets
); the union of two subsets ![]() and
and ![]() is just
is just
![]() x.
x.![]() (x)|
(x)|![]() (x).
Notice that being given the fact that
(x).
Notice that being given the fact that ![]() is in a subset includes being given the proof that it is. Of
course, one can still use the set type in this context to hide
information when desired.
is in a subset includes being given the proof that it is. Of
course, one can still use the set type in this context to hide
information when desired.
Theories
In section 10.2
the use of extractions to keep the size of objects down was described;
we now describe another important advantage of this scheme. The conclusion of the
theorem from which an object is extracted gives a type for the object,
and this type is used by a special tactic which proves the
numerous ``membership'' subgoals (i.e., those of the form ![]() »
»![]() in
in ![]() )
that arise in virtually
every proof. As briefly mentioned in chapter 9, this tactic works by
repeatedly breaking down the conclusion using intro rules until
the goals are trivial. Some of the intro rules require using
terms as parameters, and these require types to be assigned to components
of the conclusion of the goal; this task can be much easier when the extraction
scheme is used, since it in effect supplies types for the important objects
of the theory. When a theory is structured in this way, the membership
tactic is able to prove most, and in some cases all (as in the theory of regular sets
described in the next chapter), of the membership subgoals.
)
that arise in virtually
every proof. As briefly mentioned in chapter 9, this tactic works by
repeatedly breaking down the conclusion using intro rules until
the goals are trivial. Some of the intro rules require using
terms as parameters, and these require types to be assigned to components
of the conclusion of the goal; this task can be much easier when the extraction
scheme is used, since it in effect supplies types for the important objects
of the theory. When a theory is structured in this way, the membership
tactic is able to prove most, and in some cases all (as in the theory of regular sets
described in the next chapter), of the membership subgoals.
Proving such subgoals is tedious, and they arise often, so the use of extractions as previously described is almost a necessity for any serious user. Also, because a reference to an extraction contains the name of the theorem extracted from, tactics examining terms have ``hooks'' into the library available to them. Certain kinds of facts are naturally associated with defined objects. For example, a defined object which is a function may also be functional over a domain with a different equality. Using conventions for the naming or placement of such facts can allow tactics to locate required information for themselves without requiring the user to explicitly supply lemma names. The convention could be that such facts are named using a certain extension to the name of the theorem extracted from, or that such facts are located in the library close to that theorem. Obviously this is far from being a solution to the problem of knowledge management; in the design of the future versions of the Nuprl system this problem will receive considerable attention.
There are a few minor points to keep in mind when putting together a substantial theory. First, be careful with the ordering of library objects. Other objects which are referenced in a given object must precede the given object in the library. ML objects can be particularly troublesome: if you modify and recheck an ML function then the change will not be reflected in an ML function which references it. There will be nothing to indicate that the second object should be rechecked, and until it is it will continue to refer to the old version of the modified function. Another problem is that deleting an ML object from the library does not undo the bindings created therein. Thus you can check the entire library (using, say, check first-last) without an error but then have errors occur when the same library is loaded into a fresh Nuprl session. Currently, the only way to solve these problems is by being careful of organization and by keeping track of the dependencies yourself.
Footnotes
- ... subgoal.10.1
- For example, doing intro's on a universally quantified formula generates as many subgoals of this form as there are quantified variables.
- ... nontrivial.10.2
- Proving
that a type of the form
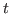 in
in 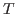 is well-formed, for instance, requires proving that
is a member of , and this can be a Nuprl statement that a program meets its specifications.
is well-formed, for instance, requires proving that
is a member of , and this can be a Nuprl statement that a program meets its specifications.