
The Book
Implementing Mathematics with The Nuprl Proof Development System
See title page for important information about this reference
Next: Building Theories Up: Index Previous: The Rules Contents
- An Overview of ML
- Functional Style
- Type Definitions
- Polymorphic Typing
- Failures
- Syntax and Semantics
- Using ML in Nuprl
- Tactics in ML
- Basic Types in ML for Nuprl
- Tools for Tactic Writers
- Example Tactics
- Existing Tactics
The Metalanguage
This chapter explores the metalanguage, ML, and its relationship to the object language, Nuprl. It examines details of the interface and explains how ML allows extensions to the deductive apparatus. Beginning with a brief summary of ML as a general purpose language, the chapter presents a detailed look at tactics, which are functions for developing proofs, and describes tools for writing tactics and ways to combine tactics. The chapter concludes with some example tactics.
An Overview of ML
This section gives a brief summary of the features of ML. For a complete account the reader is referred to the book Edinburgh LCF [Gordon, Milner, & Wadsworth 79]. Originally, ML was developed as the metalanguage for the LCF proof system; several dialects of the language have since evolved, including Cambridge ML, the implementation of ML used in Nuprl. The ML used in Nuprl differs in several minor ways from the original ML, for we have specialized the language to the Nuprl logic.The principal features of ML are:
- a functional style including the ability to use functions as values;
- a mechanism allowing the definition of new (abstract) data types;
- a polymorphic type discipline; and
- an exception-trap mechanism.
Functional Style
Functions are defined using either an abstraction construct or an equational definition. The latter form can also be used to define functions by recursion. Strictly speaking, ML does allow imperative features such as assignment, but these are almost never used in applications of ML to Nuprl.
Type Definitions
The basic ML data types are tokens, integers, booleans and a special type written ``.'' whose only member is ``()''. The other basic data types include character strings (surrounded by back quotes; for example, `PRODUCT` is a token in ML), integers and boolean values, respectively.
ML provides the user with a facility for building more complex types from simpler ones by means of type constructors that build the types inhabited by complex values. For example, the unary constructor list builds the type of lists of its argument type. The type constructors available are:
| # | the product type constructor; | |
| the sum type constructor; | ||
| list | the list type constructor; and | |
| the function type constructor. |
The user may assign names for types built with the type constructors using the lettype construct.
The types built using the type constructors described above are inhabited by data built using constructors. The most commonly used ones are:
| , | the tuple constructor; | |
| inl, inr | the constructors for the (disjoint) sum type; and | |
| . | the list constructor analogous to (infix) ``cons''. |
The corresponding destructor functions decompose structured values. It is also possible to build structures, called varstructs, containing variables; these structures may then be matched with a similarly structured expression to obtain bindings for the embedded variables. All the identifiers used in a varstruct must be distinct. For example, the varstruct [u;v] can be matched to the expression [1;2], resulting in u being bound to 1 and v being to 2. If the match is not possible, an error is returned.
The user can also build new types using the abstype construct. As the name suggests, the form of the definition is in the style of an ``abstract'' data type; there are functions that translate between the new data type and its representation (which are visible only in the definition) and functions on the new type which are available throughout the scope of the definition. The defined type can be recursive if we use absrectype instead of abstype.

The type system of ML is partially described in figure 9.1. In addition to the types in figure 9.1 the metalanguage of Nuprl contains special basic types which are used for writing tactics. These include the types proof, tactic and goal. A complete discussion of these types is contained in section 9.3.
Polymorphic Typing
The ML system associates a type with every value, including
functions, using Milner's
type-checking algorithm; thus the programmer is usually not required
to declare types explicitly. Furthermore, the type assignment is polymorphic; a given value may have a number of
different types associated
with it.
Essentially, the ``degree of freedom''
of type
assignments corresponds to the presence of type variables
in the
type expressions. For example, the identity function ![]() can be
used on any type; we do not need to define different identity functions for
each type. Thus, the type associated with the identity function is
can be
used on any type; we do not need to define different identity functions for
each type. Thus, the type associated with the identity function is
![]() , where the
, where the ![]() is a type variable.9.1A more interesting example
is the list constructor ``.''. This has type
is a type variable.9.1A more interesting example
is the list constructor ``.''. This has type
![]() . The user may also define an append function that
``glues'' two lists together;
the system would
assign to it the type
. The user may also define an append function that
``glues'' two lists together;
the system would
assign to it the type
![]() .
Note that if
an attempt is made to use the append function to concatenate a list of
integers with a list of tokens, a type error will result.
.
Note that if
an attempt is made to use the append function to concatenate a list of
integers with a list of tokens, a type error will result.
Failures
ML has a sophisticated exception-handling facility. Certain functions yield runtime errors on certain arguments and are therefore said to fail on these arguments. The result of a failure is a token, usually the function name. The token returned by a failure can be specified by using the construct failwith in a fashion to be described later.
A special operator ![]() allows one to ``catch'' failures. The
combination
allows one to ``catch'' failures. The
combination ![]() has the value
has the value ![]() unless
unless ![]() results in a failure, in
which case it has the value of
results in a failure, in
which case it has the value of ![]() .
As we shall see,
the exception-trap mechanism is useful in writing tactics.
.
As we shall see,
the exception-trap mechanism is useful in writing tactics.
Syntax and Semantics
Figure 9.2 gives a summary of the basic constructs needed for programming in ML. An abstract syntax of ML expressions is summarized in figure 9.3, with expressions shown in order of decreasing precedence. These are essentially taken from [Gordon, Milner, & Wadsworth 79]. In addition to the expression forms shown in figure 9.3, ML contains the standard arithmetic and logical operators9.2 and the equality predicate written in the traditional infix form. The various let forms have corresponding where forms in which the expression and the binding surround the where. For example, instead of let x=3 in e one could write e where x=3. The where constructs bind more tightly than the let constructs.
![\begin{figure}\hrule
\vspace{2pt}
\par
\begin{tabular}{ll}
Declarations &\\
&\\...
...dots$;vn] & list of n elements\\
\end{tabular}
\vspace{2pt}
\hrule
\end{figure}](img775.png)

The semantics of ML can be given in terms of the store-environment model. Evaluation of expressions takes place in an environment, which is a mapping between identifiers and either values or locations; the store is a mapping between locations and values and is only needed to understand imperative constructs. Evaluating an expression in an environment produces a value or a failure. In the latter case a failure token, which may be used as a value in the rest of the program, is produced.
A declaration changes the
environment. The general form
of a declaration is let b,
letref b or
letrec b, where
b is a binding. (Bindings
are described later.) If a let, is used the
identifiers in b
cannot be updated; if assignable variables are required then letref
must be used. The letrec form must be used
with recursively defined
functions. Bindings, like varstructs, have three general forms.
There are simple
bindings, function definitions and multiple bindings. The
multiple binding is just an abbreviation for a sequence of simple bindings.
In a simple binding a varstruct is equated to
an expression. The form of the varstruct and of the expression are compared,
and if they match structurally then the variables in the varstruct are bound
to the corresponding substructures of the expression.
The scope of the binding produced by
an expression of the form let x=![]() in
in ![]() is the expression
is the expression ![]() .
A
declaration of the form let x=
.
A
declaration of the form let x=![]() has scope throughout the rest of the
session until another declaration causes global
rebinding of the variables in x.
Type declarations are effected using the lettype, abstype
and absrectype forms.
The scope of the bindings associated with these terms
mirrors that of data bindings described above;
type bindings are described in more detail in [Gordon, Milner, & Wadsworth 79].
has scope throughout the rest of the
session until another declaration causes global
rebinding of the variables in x.
Type declarations are effected using the lettype, abstype
and absrectype forms.
The scope of the bindings associated with these terms
mirrors that of data bindings described above;
type bindings are described in more detail in [Gordon, Milner, & Wadsworth 79].
The evaluation of expressions is more or less standard and will only be discussed briefly. The evaluation of a constant expression returns the value denoted by the constant. The evaluation of a simple variable returns the value to which the variable is bound. The evaluation of an application, f e, results in the evaluation of f, which must be a function, the subsequent evaluation of e and finally the evaluation of the resulting application. The evaluation of the logical expressions e1 or e2 and e1 & e2 forces evaluation of e1 first and only causes the evaluation of e2 if the value of the logical expression is not determined by the value of e1. In a sequencing expression of the form e1;e2;e3...;en the expressions are evaluated in the given order and the value resulting from the evaluation of en is returned. The list construct is evaluated similarly; the evaluation of an expression of the form [e1;e2;...;en] results in the evaluation of the expressions e1 through en in that order, with the value returned being the list formed from the values of the expressions. The order of evaluation is not important unless assignable variables are being updated in the subexpressions. The evaluation of failwith e causes the evaluation of e first, after which a failure (rather than an ordinary value) with the value of e is returned. For operational descriptions of other ML constructs, see [Gordon, Milner, & Wadsworth 79].
Using ML in Nuprl
ML can be used in conjunction with the Nuprl system in a variety of
ways. The easiest way to invoke ML is to give the
command ml in the
command window;
this invokes an interactive ML interpreter.
Expressions for evaluation are typed at the
M![]() prompt and ended with ;; followed by a carriage return.
Figure 9.4 illustrates some examples
of using ML from the Nuprl command window. The user's input is on lines
indicated with M>, while the system responds on the line below with the
value of the expression (except when the expression is a function) and the
type of the expression. Note how a polymorphic expression is typed in the
third example.
prompt and ended with ;; followed by a carriage return.
Figure 9.4 illustrates some examples
of using ML from the Nuprl command window. The user's input is on lines
indicated with M>, while the system responds on the line below with the
value of the expression (except when the expression is a function) and the
type of the expression. Note how a polymorphic expression is typed in the
third example.
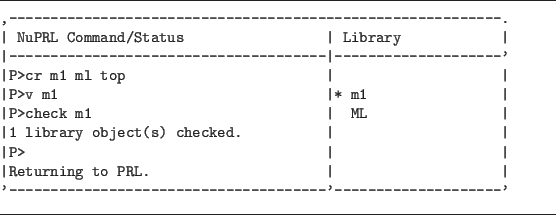
Another way to invoke ML is to use the create command to create an object of ML type as in the following example.
create m1 ml top
One can then invoke the text editor on the object using the view command.
The body of an ML program can be written, and the result can be checked
using the check command in the Nuprl command window. This process is
illustrated in figure 9.5.

Tactics in ML
Conceptually it is convenient to think of tactics as mappings from proofs to proofs. The actual implementation of tactics, however, is not quite that simple. The actual type of tactics is9.3
tactic = proof -> proof list # validation,
where proof is the type of (possibly incomplete) proofs and
validation = proof list -> proof.
The idea is that a tactic decomposes a goal proof ![]() into a
finite list of subgoals,
into a
finite list of subgoals,
![]() , and a
validation,
, and a
validation, ![]() . The
subgoals are degenerate proofs, i.e., proofs which have only the top-level
sequent filled in and have no refinement rule or subgoals.
We say that a
proof
. The
subgoals are degenerate proofs, i.e., proofs which have only the top-level
sequent filled in and have no refinement rule or subgoals.
We say that a
proof ![]() achieves
the subgoal
achieves
the subgoal ![]() if the
top-level sequent of
if the
top-level sequent of ![]() is the same as the top-level sequent of
is the same as the top-level sequent of ![]() .
The validation,
.
The validation, ![]() , takes a list
, takes a list
![]() ,
where each
,
where each ![]() achieves
achieves ![]() ,
and produces a proof
,
and produces a proof ![]() that achieves
that achieves ![]() . (Note that wherever we
speak of proof in the context of ML, we mean possibly incomplete proofs.)
. (Note that wherever we
speak of proof in the context of ML, we mean possibly incomplete proofs.)
Thus a tactic completes some portion of a proof and produces
subgoals that it was unable to prove completely and a
validation that will take any achievement of those subgoals and produce an
achievement of the original goal. If the validation is applied to
achievements
![]() that are complete proofs, then the result of
the validation is a complete proof of the goal G. In particular, if the
tactic produces an empty list of subgoals then the validation applied to
the empty list produces a complete proof of the goal.
that are complete proofs, then the result of
the validation is a complete proof of the goal G. In particular, if the
tactic produces an empty list of subgoals then the validation applied to
the empty list produces a complete proof of the goal.
The advantage of this system becomes apparent when one composes tactics. Since a tactic produces an explicit list of subgoals a different (or the same) tactic can easily be applied to each of the subgoals; the tactics thus decompose goals in a top-down manner. This makes it easy to write specialized and modular tactics and to write special tacticals for composing tactics. This system has the disadvantage, however, that it does not easily accommodate a bottom-up style of tactic.
The Nuprl system recognizes two kinds of tactics: refinement tactics and transformation tactics. A refinement tactic operates like a derived rule of inference. Applying a refinement tactic results in the name of the tactic appearing as the refinement rule and any unproved subgoals produced by the tactic appearing as subgoals to the refinement. The following are the actual steps that occur when a refinement tactic is invoked.
- The ML variable prlgoal is associated with the current sequent,
which is viewed as a degenerate proof. Note that there may be a refinement
rule and subgoals below the sequent but that these are ignored as
far as refinement tactics are concerned.
- The given tactic is applied to prlgoal, producing a (possibly
empty) list of unproved subgoals and a validation.
- The validation is applied to the subgoals.
- The tactic name is installed as the name of the refinement rule in the
proof. The refinement tree that was produced by the validation in the
previous step is stored in the proof, and any remaining unproved subgoals
become subgoals of the refinement step.
The four steps above assume that the tactic terminates without producing an error or throwing a failure that propagates to the top level. If such an event does occur then the error or failure message is reported to the user and the refinement is marked as bad; this behavior exactly mimics the failure of a primitive refinement rule.
Transformation tactics have the effect of mapping proofs to proofs. The result of a transformation tactic is spliced into the proof where the tactic was invoked and takes the place of any previous proof. The following are the steps that occur when a transformation tactic is invoked.
- The ML variable prlgoal is associated with the proof below, and
including, the current sequent.
- The specified transformation tactic is applied to prlgoal,
producing a (possibly empty) list of subgoals and a validation.
- The validation is applied to the list of subgoals.
- The proof that is the result of the previous step is grafted into
the original proof below the sequent.
The key difference between refinement and transformation tactics is that transformation tactics are allowed to examine the subproof that is below the current node whereas refinement tactics are not. The result of a transformation tactic will, in general, depend upon the result of the examination. Since most tactics do not depend on the subproof below the designated node, they may be used as either transformation tactics or refinement tactics; in fact, since a refinement tactic cannot examine the subproof, any refinement tactic may be used as a transformation tactic. The main implementation difference between refinement tactics and transformation tactics is how the result of the tactic is used. In the former the actual proof constructed by the tactic is hidden from the user, and only the remaining unproved subgoals are displayed. In the latter the result is explicitly placed in the proof.
Basic Types in ML for Nuprl
In specializing the ML language to Nuprl we have made each of the kinds of objects that occur in the logic into ML base types. The ML type proof has already been encountered. There are also types for terms, rules and declarations (see figure 9.6). These types should not be confused with types of the Nuprl logic; the types described here are data types in the programming language ML that represent objects of the logic.
![\begin{figure}\hrule
\begin{description}
\par
\item [{\tt proof:}] Type of part...
...{\tt term:}] Terms of the logic.
\par
\end{description}\par\hrule
\end{figure}](img783.png)
For each of the types there is an associated collection of predicates, constructors and destructors. The predicates on the type term, for example, allow the kind of a term to be determined. An example of a predicate on terms is is_universe_term, which returns true if and only if the term it is applied to is a universe term. The constructors and destructors for each of the types allow new objects of the types to be synthesized and existing objects of the type to be divided into component parts. Appendix A contains a list of primitive extensions to ML that have been made in implementing Nuprl tactics.
Proofs
We think of proofs as a recursive data type whose components are as follows.
- A list of declarations.
- These represent the hypotheses of the
top-level sequent of the proof.
They are accessed with the function hypotheses,
which maps proofs to a list of terms.
- A term.
- The goal of the top-level sequent. It is accessed with
the function conclusion.
- A rule.
- The top-level refinement rule. This will be missing when
the goal has not been refined. It is accessed with the function refinement. The function fails if there is no refinement.
- A list of proofs.
- The subgoals to the refinement, if any. They are accessed with the function children. The function fails if there is no refinement.
For the ML type proof a complement of destructors are available that allow the conclusion, hypotheses (declarations), rule and children to be extracted from a proof. There is only one primitive function in ML that constructs new proof objects; that is refine. The function refine maps rules into tactics and forms the basis of all tactics. When supplied with an argument rule and proof, refine performs, in effect, one refinement step upon the sequent of the proof using the given rule. The result of this is the typical tactic result structure of a list of subgoals paired with a validation. The list of subgoals is the list of children (logically sequents, but represented as degenerate proofs) resulting from the refinement of the sequent with the rule.
The function refine is the representation of the actual Nuprl logic in ML, for every primitive refinement step accomplished by a tactic will be performed by applying refine. The subgoals of the refinement are calculated by the Nuprl refinement routine, deduce_children, from the proof and the rule. Constructing the validation, an ML function, is more complicated. Given achievements of the subgoals, the purpose of the validation is to produce an achievement of the goal. The validation therefore constructs a new proof node whose sequent is the sequent of the original goal, whose refinement rule is the rule supplied as an argument to refine, and whose children are the achievements (partial proofs) of the subgoals.
The user will probably never construct or use a validation except to apply one to a list of achievements; all the validations one will probably use will be constructed by refine and by standard tacticals. The important thing to know about validations is that they cannot construct incorrect proofs. This is enforced by the strong type structure of ML and by the interface between Nuprl and ML. See [Constable, Knoblock, & Bates 84] for an account of how the correctness of proofs is ensured.
The function refine_using_prl_rule is a composition of refine and another ML function, parse_rule_in_context. This function takes a token (the ML equivalent of a string) and a proof and produces a rule. It uses the same parser that is used when a rule is typed into the proof editor. This allows one to avoid using the explicit rule constructors, although efficiency is lost. Note that the proof argument is used to disambiguate the rules.
In addition to refine there is one other basis tactic, IDTAC, which is the identity tactic. The result of applying IDTAC to a proof is one subgoal, the original proof, and a validation that, when applied to an achievement of the proof, returns the achievement. The function IDTAC is useful since it may serve as a no-op tactic.
Rules
The rule constructors in ML do not correspond precisely to the rules in Nuprl. Refinement rules in Nuprl are usually entered as ``intro'', ``elim'', ``hyp'', etc. Strictly speaking, the notation ``intro'' refers not to a single refinement rule but to a collection of introduction refinement rules, and the context of the proof is used to disambiguate the intended introduction rule at the time the rule is applied to a sequent. There is a similar ambiguity with the other names of the refinement rules. In addition to this ambiguity, the various sorts of the rules require different additional arguments. For example, applying an intro rule to ``»1 in int'' requires no further information, but applying intro to ``»int'' requires that an integer be given. Because rules in ML may exist independently of the proof context that allows the particular kind of rule to be determined, and because functions in ML are required to have a fixed number of arguments, the rule constructors have been subdivided beyond the ambiguous classes that are normally visible to the Nuprl user. For example, there are constructors like universe_intro_integer, product_intro and function_intro, all of which are normally designated in proof editing with intro. The ML rule constructors and destructors are listed along with the inference rules in chapter 8.
Declarations
The constructor for declarations, construct_declaration, takes
a pair of type tok#term and produces a declaration. The token
represents the variable name in the declaration. The general destructor,
destruct_declaration, maps a declaration into pair of type tok#term. The ML function
id_of_declaration maps a declaration into
a token representing the variable of the declaration, and the function type_of_declaration maps a declaration to the term of the declaration.
Terms
The type of terms is a recursive data type; it is a variant union based upon the type of term: universe, function, product, etc. The function term_kind returns the kind of the term as a token: `UNIVERSE`,`FUNCTION` or `PRODUCT`, for example. Corresponding to each kind of terms is a boolean predicate: is_universe_term, is_function_term and is_product_term, for example.
For each kind of term there is a constructor and a destructor. For example, for universe terms the constructor, make_universe_term, maps integers (representing universe levels) to terms. The corresponding destructor is destruct_universe and maps terms to integers. The destructor fails if applied to a term that is not a universe term, and the constructors for terms fail if the semantic restrictions on the arguments are not met. For example, destruct_universe fails if applied to a nonpositive integer since it is not a legal universe level.
Nuprl defs used to construct terms are invisible to ML. Terms are, in fact, composed of two parts: an underlying term structure and a print representation. The constructors and destructors described above operate on the term structure; in the case of the constructors a reasonable print representation is calculated automatically. See below for how to examine the print representation of a term.
In addition to the individual term constructors, constant terms may be used by entering any legal Nuprl term enclosed in single quotes, as in 'int in U7'. Note that these quotation marks are different from those used for tokens in ML.
Print Representation
For the types of term, rule and declaration, the print representation of the object can be accessed using the functions term_to_tok, rule_to_tok and declaration_to_tok, respectively. These are the representations that would be used if the object were displayed by the Nuprl proof editor. This gives one a rudimentary way to check for defs.
A Note about Equality
In
ML two objects of type term are equal if and only if they are
![]() -convertible variants of each other. That is, they are equal if and
only if the
bound variables can be renamed so that the terms are identical. For objects
of type proof, rule and declaration, two objects are equal
if and only if they are the same object.
-convertible variants of each other. That is, they are equal if and
only if the
bound variables can be renamed so that the terms are identical. For objects
of type proof, rule and declaration, two objects are equal
if and only if they are the same object.
Tools for Tactic Writers
In this section we summarize some of the more important tools that have been included in the system to aid in writing tactics.
Tacticals
Tacticals allow existing tactics to be combined to form new tactics. In chapter 6 we saw several example tactics formed by refine_using_prl_rule and the tacticals THEN, ORELSE and REPEAT. In this section we summarize all of the currently existing tacticals.
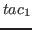 THEN
THEN 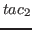 :
:- The THEN
tactical is the composition functional for tactics.
THEN defines a tactic
which when invoked on a proof first applies and then, to each
subgoal produced by , applies .
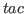 THENL
THENL 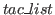 :
:- The THENL
tactical is similar to the
THEN tactical except that the second argument is a list of tactics
rather than just one tactic. The resulting tactic applies , and
then to each of the subgoals (a list of proofs) it applies the corresponding
tactic from . If the number of subgoals is different from
the number of tactics in , the tactic fails.
- ORELSE :
- The
ORELSE tactical creates a tactic
which when applied to a proof first applies . If this application
fails, or fails to make progress,
then the result of the tactic is the application of to the
proof. Otherwise it is the result that was returned by . This
tactical gives a simple mechanism for handling failure of tactics.
- REPEAT :
- The REPEAT
tactical will repeatedly apply
a tactic until the tactic fails. That is, the tactic is applied to the goal
of the argument proof, and then to the subgoals produced by the tactic, and
so on. The REPEAT tactical will catch all failures of the argument
tactic and can not generate a failure.
- COMPLETE :
- The COMPLETE
tactical constructs a tactic
which operates exactly like the argument tactic except that the new tactic
will fail unless a complete proof was constructed by , i.e.,
the subgoal list is null.
- PROGRESS :
- The PROGRESS
tactical constructs a tactic
which operates exactly like the argument tactic except that it fails unless
the tactic when applied to a proof makes some progress toward a proof. In
particular, it will fail if the subgoal list is the singleton list
containing exactly the original proof.
- TRY :
- The TRY
tactical constructs a tactic which
tries to apply to a proof; if this fails it returns the result
of applying IDTAC to the proof. This insulates the context in which
tac is being used from failures. This is often
useful for the second argument of an application of the THEN
tactical.
Substitution
Two functions currently perform substitutions in terms: substitute and replace. Both take a term and a substitution as arguments and produce a term, where a substitution is a list of pairs, the first element of which is a term representing the variable to be substituted for and the second element of which is the term to substitute for that variable. The function substitute will automatically rename bound variables in order to avoid capture in the term during the substitution,9.4while the function replace will perform a substitution without regard to capture.
Unification
The function unify is a unification function for terms. This function takes two terms and produces the most general unifier (a substitution) such that if a replace is performed on each of the terms using the unifier, the result is the same term. The unification function fails if there is no unifier. This function provides a simple way to decompose terms without using the term destructors. The only variables that will be substituted for are those whose names are preceded by an underscore, e.g., ``_meta''. For example,
unify 'x:int#(x=x in int)' '_var:_left_type#_right_type'
results in the unifier
[('_var', 'x');
('_left_type', 'int');
('_right_type', '(x=x in int)')].
Example Tactics
A few examples should give enough of the flavor of tactic writing in the Nuprl context to permit the reader to build substantial tactics of his own. Our first example is a very simple one which encodes a frequently used pattern of reasoning, namely, case analysis. When called as a refinement tactic with an argument which is a union type (i.e., of the form A|B) cases will do a seq with its argument and then do an elim on the copy of the term which appears in the hypothesis list of the second subgoal. The effect is essentially to implement a derived rule of the form
>> T by cases 'A|B'
>> A | B
A >> T
B >> T
except that any of the subgoals which the auto-tactic manages
to prove will not appear.
(Note the use of the quotes to make text into an ML term.)
The following is the implementation of the tactic.
let cases union_term =
refine (seq [union_term] [`nil`])
THENL
[IDTAC
;\pf.
refine (union_elim (length (hypotheses pf)) `nil` `nil`)
pf
]
THEN
TRY (COMPLETE immediate)
;;
The first refine above will do the seq rule;
the `nil` argument means that the new hypothesis in the
second subgoal generated will not have a tag. The two members of
the list following the THENL are what will be applied to the
two subgoals resulting from the seq. The first one
simply leaves alone the introduced union term, and the
second does the elimination. The only complication is that
the rule constructor union_elim requires the number of the
hypothesis to be eliminated as an argument; in this case it is the last one,
so the length of the current hypothesis list is the required
number.
Since the length of the actual proof to which refine is
applied is necessary, the second tactic in the list of tactics is actually
a lambda term.
Recall that the type of tactics is proof->proof list # validation.
Therefore, if ![]() is a piece of ML code which uses
an identifier pf and which is of type tactic
under the assumption that pf is of type proof, then
is a piece of ML code which uses
an identifier pf and which is of type tactic
under the assumption that pf is of type proof, then
![]() pf.(
pf.(![]() pf) is also a tactic. When it is applied to
a proof pf will be bound to the proof, and then
the tactic defined by
pf) is also a tactic. When it is applied to
a proof pf will be bound to the proof, and then
the tactic defined by ![]() will be applied.
In the last line an attempt is made to
prove completely all of the unproved subgoals generated so far.
will be applied.
In the last line an attempt is made to
prove completely all of the unproved subgoals generated so far.
The next example illustrates some of the other functions available in the ML environment of Nuprl. Given an integer, bring_hyp returns a refinement tactic implementing the rule
>> T' by bring_hyp i
>> T->T'
where T is the type in hypothesis i.
This is often useful when it is desired that the substitutions
done by an elimination be done in a hypothesis also; using
this tactic, doing the elimination and then doing an introduction
accomplishes this.
![\begin{figure}\hrule
\begin{verbatim}let bring_hyp hyp_no proof =
let hyp_te...
...)
THEN immediate
]
) proof
;;\end{verbatim}
\vspace{2pt}
\hrule
\end{figure}](img789.png)
Figure 9.7 shows the implementation of this tactic.
The function select takes an integer ![]() and
a list and returns the
and
a list and returns the ![]() element of the list, and
type_of_declaration breaks down a declaration into
its two components and returns the second part. make_function_term
takes an identifier
element of the list, and
type_of_declaration breaks down a declaration into
its two components and returns the second part. make_function_term
takes an identifier ![]() and terms
and terms ![]() and
and ![]() to a term
to a term ![]() :
:![]() ->
->![]() .
Note that because of the intended purpose of the tactic
no attempt is made to prove one of the generated subgoals.
.
Note that because of the intended purpose of the tactic
no attempt is made to prove one of the generated subgoals.
Example Transformation Tactics
To illustrate the use of transformation tactics we examine a pair of tactics, mark and copy, that can be used to copy proofs. To use these tactics the user locates the proof he wants to copy and invokes the mark tactic as a transformation tactic. He then locates the goal where he wants the proof inserted and invokes copy as a transformation tactic. The application of mark does not change the proof and records the proof in the ML state so that it is available when the copy tactic is used. Note that the goal of the proof where the copied proof is inserted cannot be changed by the copy tactic.
The mark tactic is defined as follows. The variable saved_proof is a reference variable of type proof.
let mark goal_proof =
(saved_proof := goal_proof;
IDTAC goal_proof
);;
The basis of the copy tactic is a verbatim copy of the saved proof. This is accomplished by recursively traversing the saved proof and refining using the refinement rule of the saved proof. The following is a first approximation of the copy tactic.
letrec copy_pattern pattern goal =
(refine (refinement pattern)
THENL (map copy_pattern (children pattern))
) goal;;
let copy goal = copy_pattern saved_proof goal;;
This version of copy will fail if the saved proof is incomplete since the selector refinement fails if applied to a proof without a refinement rule. To correct this deficiency we define a predicate is_refined and change copy_pattern to apply immediate where there is no refinement in the saved proof.
letrec copy_pattern pattern goal =
if is_refined pattern then
(refine (refinement pattern)
THENL (map copy_pattern (children pattern))
) goal
else
immediate goal;;
With this as a basis any number of more general proof-copying tactics can be defined. For example, the following version of copy looks up the actual formula being referenced in elimination rules, rather than just the index in the hypothesis list, and locates the corresponding hypothesis in the context where the proof is being inserted. Furthermore, if one of the refinements from the pattern fails in the new context then immediate is tried.
letrec copy_pattern pattern goal =
if is_refined pattern then
(refine (adjust_elim_rules pattern goal)
THENL (map copy_pattern (children pattern))
ORELSE immediate
) goal
else
immediate goal;;
The function adjust_elim_rules checks if the refinement is an elimination rule. If the refinement is not an elimination, the function returns the value of the rule unchanged. If it is an elimination rule, the tactic looks up the hypothesis in the pattern indexed by the rule and finds the index of an equal hypothesis in the hypothesis set of the goal. In this case the value returned is the old elimination rule with the index changed to be the index in the hypothesis set of the goal rather than the pattern.
A Larger Example
We end this section with a somewhat larger example; backchain_with is a tactic that implements backchaining, a restricted form of resolution. It tries to prove the goal by ``backing through'' hypotheses, i.e., by finding a hypothesis that is an implication whose consequent matches the conclusion of the goal, and then recursively calling itself to prove the antecedents of the implication.
The main component is back_thru_hyp, which, given i, proceeds as
follows. First, it uses match_part to match the conclusion
against part of hypothesis i; if the hypothesis has the form ![]() :
:![]() ->
-> ![]() ->
-> ![]() :
:![]() -> (
-> ( ![]() &
& ![]() &
& ![]() ) (where some of the variables may not be present), and if terms can be
obtained that, when substituted for the
) (where some of the variables may not be present), and if terms can be
obtained that, when substituted for the ![]() in one of the
in one of the ![]() , yield
the conclusion, then match_part succeeds and returns those terms.
The terms are used to obtain instances of the
, yield
the conclusion, then match_part succeeds and returns those terms.
The terms are used to obtain instances of the ![]() (antecedents). If
(antecedents). If ![]() then the goal can be proved immediately; otherwise,
a tactic based on the seq rule is used to obtain the subgoals that the
seq rule would produce, except that all but the last of the subgoals
have no extra hypotheses. The last of these subgoals is completely
proved using repeated eliminations; of the rest, the ones
which have conclusions of the form
then the goal can be proved immediately; otherwise,
a tactic based on the seq rule is used to obtain the subgoals that the
seq rule would produce, except that all but the last of the subgoals
have no extra hypotheses. The last of these subgoals is completely
proved using repeated eliminations; of the rest, the ones
which have conclusions of the form
![]() in
in ![]() are
left for the membership tactic, and
backchain_with is recursively applied to the remainder.
are
left for the membership tactic, and
backchain_with is recursively applied to the remainder.
When invoked, backchain_with first breaks down the conclusion
and then tries to back through each
hypothesis in turn until it succeeds; if it does not, the tactic
tactic is applied. If tactic is \p.fail then backchain_with behaves like a primitive Prolog
interpreter, where the hypotheses are the clauses and the conclusion is
the query. The fact that backchain_with
takes a tactic as an argument
allows one to make this basic search method more powerful, since it
means that one can specify what actions to take at the ``leaves''
of the search.
letrec backchain_with tactic =
let atomize_concl =
REPEAT
(\ p . let c = concl p in
if is_function_term c or is_and_term c
then intro p else fail
) in
let back_thru_hyp i p =
let t = type_of_hyp i p and c = conclusion p in
let inst_list = match_part c t in
let antecedents = antecedents t inst_list in
( if null antecedents then
repeat_and_elim i
THEN
hypothesis
else
parallel_seq antecedents
THEN
(\ p . (if conclusion p = c then
repeat_function_elim i inst_list
THEN
( hypothesis
ORELSE
( apply_to_last_hyp repeat_and_elim
THEN
hypothesis
)
)
else
if_not_membership_goal
(backchain_with tactic)
) p
)
) p in
atomize_concl
THEN
if_not_membership_goal
(apply_to_a_hyp back_thru_hyp ORELSE tactic)
;;
Existing Tactics
This section describes some of the tactics which have been written so far. If you have a copy of the system you should find most, if not all, of the described tactics in the ML files that come with it. Since these files for the most part are fairly well documented, and since the tactic collection is not stable, we limit ourselves here to describing briefly some of the tactics which are particularly useful and which provide an example of what can be done. See the files for the exact names and types of the described tactics.
One of the most tedious parts of reasoning in Nuprl involves dealing with the
numerous trivial membership subgoals which arise. Looking at the rules,
one can see that many of them have subgoals of the form
![]() in U
in U![]() . Also, applying a lemma involves using the
lemma rule and then applying the elim
rule to instantiate the universally quantified variables of the lemma;
each such elim entails proving that the term introduced
to instantiate the variable is of the appropriate type. Both these
types of subgoals have the same form,
. Also, applying a lemma involves using the
lemma rule and then applying the elim
rule to instantiate the universally quantified variables of the lemma;
each such elim entails proving that the term introduced
to instantiate the variable is of the appropriate type. Both these
types of subgoals have the same form, ![]() in
in ![]() , and the vast
majority are fairly trivial. Fortunately, the tactic written to deal
with these (currently called member) has so far
been able to prove almost
all of them. This tactic repeatedly applies
intro to the membership subgoal until
the subgoal
has been broken down into components with trivial enough conclusions
(like
, and the vast
majority are fairly trivial. Fortunately, the tactic written to deal
with these (currently called member) has so far
been able to prove almost
all of them. This tactic repeatedly applies
intro to the membership subgoal until
the subgoal
has been broken down into components with trivial enough conclusions
(like ![]() in
in ![]() where
where ![]() :
:![]() is
a hypothesis) to be immediately justifiable from the hypotheses.
The hard part is guessing the using types required by many of the
intro rules; for example, the intro rule for a goal of the form
»
is
a hypothesis) to be immediately justifiable from the hypotheses.
The hard part is guessing the using types required by many of the
intro rules; for example, the intro rule for a goal of the form
» ![]() (
(![]() ) in
) in ![]() takes as a parameter the type of
takes as a parameter the type of ![]() .
It is the type-guessing component which contains
the bulk of the heuristics of the tactic. A good part of the success of
this tactic owes to the extensive use of extractions, which provide
an important source of type information; this is discussed further
in the next chapter.
.
It is the type-guessing component which contains
the bulk of the heuristics of the tactic. A good part of the success of
this tactic owes to the extensive use of extractions, which provide
an important source of type information; this is discussed further
in the next chapter.
There are several tactics whose function, in part, is to make the rules easier to use. Most of the primitive rules in Nuprl require arguments. This makes it difficult to chain them together using the tacticals, so several tactics have been written which apply an appropriate member of a class of rules and guess the arguments required. An example is the tactic intro, which handles all the introduction steps except product and set intro, where a ``witness'' term is required, and union intro, where one must decide which half to prove. These tactics also deal with noncanonical forms. That is, if a canonical form is expected, as in the case of an elimination where the hypothesis must be a canonical type, but a noncanonical form is encountered, as will often happen if one defines the basic objects of his theory to be extractions, then the tactic will first use the direct computation rules to do any necessary reduction steps.
Since the lemma rule causes the statement of the lemma to be put in the hypothesis list, proving goals whose conclusions are instances of previously proven results would be tedious without tactic support. A particularly useful tactic for this takes a theorem name and tries to match the goal's conclusion with part of the theorem in order to determine the terms with which to instantiate the theorem. If successful, the tactic will produce subgoals corresponding to the antecedents of the implication forming the theorem, the consequent of which was matched against the goal's conclusion.
Finally, we briefly discuss a set of functions which provide support for implementing term-rewriting tactics. They are slight modifications of what Paulson has written for use in LCF [Paulson 83b] and which he used to write the main tactics in his proof of the correctness of the unification algorithm [Paulson 84]. The basic idea is to use analogues of the tacticals THEN, ORELSE, etc., as the basis for constructing larger rewriting tactics from smaller ones. To this end we define a type of conversions:
lettype conv = term -> (term # tactic).
Given a term
Footnotes
- ... variable.9.1
- The system actually uses sequences of asterisks rather than Greek letters.
- ... operators9.2
- The notation for the logical ``or'' is or and for ``and'' is &.
- ... is9.3
- This is a specialization of the LCF [Gordon, Milner, & Wadsworth 79] concept of tactic in that both goal and event are taken as partial proofs.
- ... substitution,9.4
- This is usually how substitution takes place throughout the Nuprl system.